
GPT-What: Intro to the next big thing
24 Jul 2020So a few weeks ago I stumbled upon something that reminded me of Arthur C. Clarke’s famous 3rd law — Any sufficiently advanced technology is indistinguishable from magic.
It was something I’d never seen before. It was a moment where I saw a piece of complex technology becoming easily accessible and approachable to a much larger group.
Of course, I’m talking about OpenAI’s Generative Pretrained Transformer 3 or commonly known as GPT-3. OpenAI announced that they are opening up access to it through their API which is invite-only at this point.
So far I’ve seen it described as the biggest thing since the Internet, the Blockchain, and everything in between. It intrigued me to no end and I wanted to learn more. That made me go down a bit of a rabbit hole. Here’s my attempt to summarize my findings from a layman perspective.
Show me the Magic!
Before we understand what’s under the hood, let’s see this in action.
Search Engine
Here’s a demo where GPT-3 acts as a search engine that can reply with an answer to your exact query
I made a fully functioning search engine on top of GPT3.
— Paras Chopra (@paraschopra) July 19, 2020
For any arbitrary query, it returns the exact answer AND the corresponding URL.
Look at the entire video. It's MIND BLOWINGLY good.
cc: @gdb @npew @gwern pic.twitter.com/9ismj62w6l
Tabulating
Ok, so it can give me plain text answers but can it generate structured data? Yessir
=GPT3()... the spreadsheet function to rule them all.
— Paul Katsen (@pavtalk) July 21, 2020
Impressed with how well it pattern matches from a few examples.
The same function looked up state populations, peoples' twitter usernames and employers, and did some math. pic.twitter.com/W8FgVAov2f
Designing
Great so it knows Excel. But can it design a UI? Apparently, yes!
This changes everything. 🤯
— Jordan Singer (@jsngr) July 18, 2020
With GPT-3, I built a Figma plugin to design for you.
I call it "Designer" pic.twitter.com/OzW1sKNLEC
Writing Code
Alright, so it generated a few mocks. It surely can’t write code, right? Nope, it can!
I built a todo list app simply by describing it to GPT-3.
— Sharif Shameem (@sharifshameem) July 18, 2020
It generated the React code for a fully functioning app within seconds.
I'm becoming more impressed and aware of its capabilities every single day. pic.twitter.com/QGrClar03s
So you get the idea! The only limit is your imagination. So now let’s see what’s behind the curtain.
What sorcery is this?!
So the simplest way to describe what you saw in those demos would be that a computer program was fed a huge chunk of human knowledge. A user would then give it an example or two of a question-answer pair and then proceed to ask similar questions to which it will respond with accurate answers. That’s really the gist of what we are seeing in the demos.
Now let’s get a bit jargony and break that down a bit. So what is it technically? It’s an unsupervised transformer language model that contains 175 billion parameters capable of few-shot learning. Whoa okay, that sounds impressive. But what does it all mean?

First, what is a language model?
It’s a program that knows the relationships between words in a language. It knows the probability of words and sentences that should appear after another. This forms the foundation of voice recognition tech like Alexa, Siri, etc

What does it mean for it to be a Transformer?
Again, summarizing the concept in the simplest way possible. The type of language model tells us how it was trained i.e how did it come up with the relationship between words and sentences in a language. In other words, it tells us how those probabilities were calculated.
Traditionally models built on the LSTM (Long short-term memory) or CNN (Convolutional neural network) have been used but they had some significant disadvantages. First, the relationship between words and sentences would be lost the farther apart they were. Second, the processing of those sentences had to be done sequentially word-by-word which meant it was slow.
Transformer, on the other hand, is a novel architecture that was introduced in a paper titled Attention Is All You. It solved both of those challenges based on the concept of “attention” which let the model directly look at, and draw from, the state at an earlier point in the sentence.

What makes it unsupervised?
Unsupervised learning is one of the three main types of machine learning models that include supervised and reinforcement learning.
What makes it different from the other two is the fact that it doesn’t need a structured and labeled dataset nor is the algorithm incentivized for certain types of outcomes over others like for example in a game.
What are those 175 billion parameters?
GPT-3 model was given a large dataset consisting of sources such as Common Crawl, Wikipedia, WebText, Books among others worth around 45 TB of text.
When that data was analyzed, simply put, the model was able to extract 175 billion different characteristics about the dataset and establish relationships between them.
According to Geoffrey Hinton — the godfather of ‘deep learning’ — parameter can be thought of as a synapse in a human brain:
My belief is that we’re not going to get human-level abilities until we have systems that have the same number of parameters in them as the brain. So in the brain, you have connections between the neurons called synapses, and they can change. All your knowledge is stored in those synapses. You have about 1,000-trillion synapses—10 to the 15, it’s a very big number. So that’s quite unlike the neural networks we have right now. They’re far, far smaller, the biggest ones we have right now have about a billion synapses. That’s about a million times smaller than the brain.
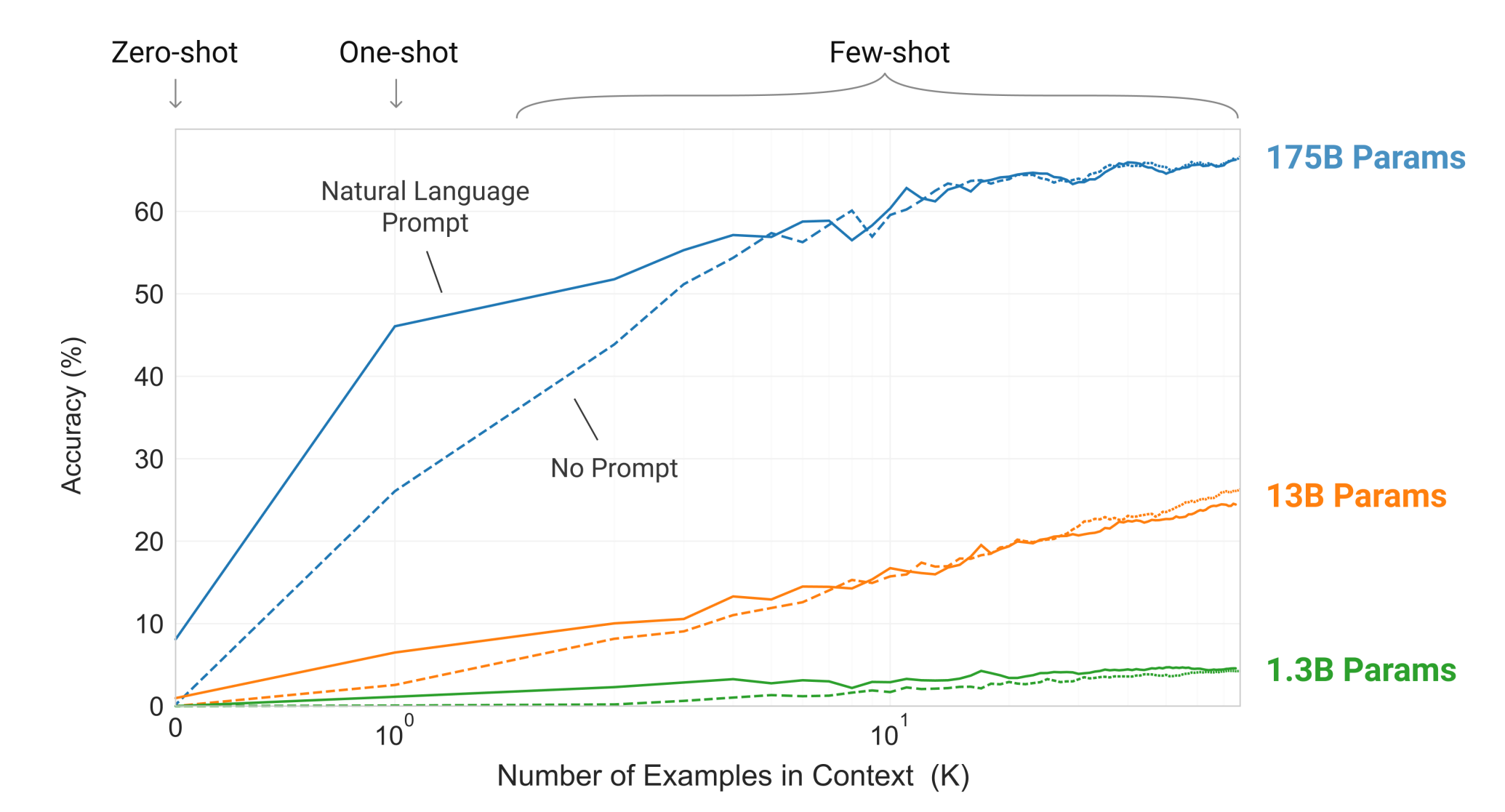
Lastly, what is few-shot learning?
In a paper titled Language Models are Few-Shot Learners researchers demonstrated that language models that have a large number of parameters like GPT-3 excel in performance even when it’s provided with very few examples of the kind of results we are expecting from it. So in other words, the more parameters it has, fewer the examples you have to provide to achieve accuracy:
Not everything that glitters is gold
Will numerous professions be put out of work? Will Skynet take over? Nope, not even close. GPT-3 while very impressive and seemingly magical has several flaws.

Data Quality & Bias
Given this model is trained on a large corpus of data on the internet, it also contains all the unpleasant things that come with it. For example, here are some instances of inherent biases and downright racist/sexist outputs:
#gpt3 is surprising and creative but it’s also unsafe due to harmful biases. Prompted to write tweets from one word - Jews, black, women, holocaust - it came up with these (https://t.co/G5POcerE1h). We need more progress on #ResponsibleAI before putting NLG models in production. pic.twitter.com/FAscgUr5Hh
— Jerome Pesenti (@an_open_mind) July 18, 2020
.@VioletNPeng wrote a paper that produced shockingly #racist and #sexist paragraphs without any cherry picking. For @OpenAI to launch this during #BlackLivesMattters is tone deaf. pic.twitter.com/6q3szp0Mm1
— Prof. Anima Anandkumar (@AnimaAnandkumar) June 11, 2020
This is no secret and OpenAI themselves warn about it in their FAQs:
How will OpenAI mitigate harmful bias and other negative effects of models served by the API?
Mitigating negative effects such as harmful bias is a hard, industry-wide issue that is extremely important. Ultimately, our API models do exhibit biases (as shown in the GPT-3 paper) that will appear on occasion in generated text. Our API models could also cause harm in ways that we haven’t thought of yet.
Priming
So a lot depends on the quality of inputs or examples you feed GPT-3 which is called “priming”. If you prime poorly, you’ll get poor results. Since the model is trained on a massive dataset, chances are, if you give it carefully curated inputs, it will likely return intelligent outputs. How well you prime this model becomes the special sauce.
Lack of competitive advantage
That brings me to my next point. Priming is the only special sauce, otherwise, everyone has access to the same model. So whatever products you build, could theoretically be easily reproducible by competitors.
3rd party models like GPT-3 can only be a value-add on top of whatever you are offering, it can’t be THE product otherwise you will quickly go out of business. This is the reason a lot of companies will continue to train custom models on private/proprietary data and hyper optimize it for the use-case they are trying to solve. That will continue to be the way forward for any serious business applications.
This may very well change in the future as their API evolves and becomes more feature-rich. Capability to fine-tune this model would almost certainly be on their roadmap to make this appealing for any serious applications.
API Limitations / Cost
Speaking of API, we still have no idea how this API will function in a production setting. What would the latency look like? What will be the associated costs? Will there be any rate limiting/throttling? What about SLA / uptime guarantees? What about data privacy and ownership of inputs and outputs?
Where do we go from here?
While there are several limitations and challenges, OpenAI has shown us what could be possible in the future.
Remember the time the iPhone was launched? Before then Moto Razr was the hottest phone to have. The phone market was slowly but incrementally making improvements. But the iPhone completely turned the market upside down. It beautifully merged some of the advancements in hardware and software up until then into one product and made it accessible to a broader market like nobody had done before.
OpenAI’s API might just be an inflection point like that. It democratizes access to AI so that a much broader group of users can easily leverage it and build applications on top of it. It has the potential to be the AWS of modeling if they add more capabilities and build a rich ecosystem.
In the coming years, we can only expect the newer iterations of this model to get more and more powerful. After all, this is only the first step in OpenAI’s mission to achieve artificial general intelligence (AGI). An AI so powerful it can understand or learn any task that a human being can — something which is deeply exciting and terrifying at the same time.
