01 Jan 2025
Exercise better foresight by identifying patterns, pinpointing what makes them persist, and understanding what could prevent it in the future.
Take a moment to count the urgent issues you handled this week. Production incidents. Customer escalations. Team conflicts. Deadline pressures. For many engineering leaders, these “firefighting” moments consume the majority of their workday, leaving little time for strategic thinking or meaningful improvements.
This constant cycle of reacting to problems is exhausting and expensive. Every hour spent handling preventable issues is an hour not spent on innovation, team development, or strategic planning. The cost compounds across your team, affecting morale, productivity, and your ability to deliver value.
But there’s a better way. By embracing systems thinking, you can transform your team from reactive to proactive, creating processes that run themselves and free you to focus on what matters most: innovation and growth.
Understanding the systems thinking iceberg
One powerful model to visualize systems thinking is the iceberg model. Just like an iceberg, where 10% is visible above water while the remaining 90% lies beneath the surface, this model reminds us that there’s much more to a situation than meets the eye. The visible problems are often symptoms of deeper, hidden issues.
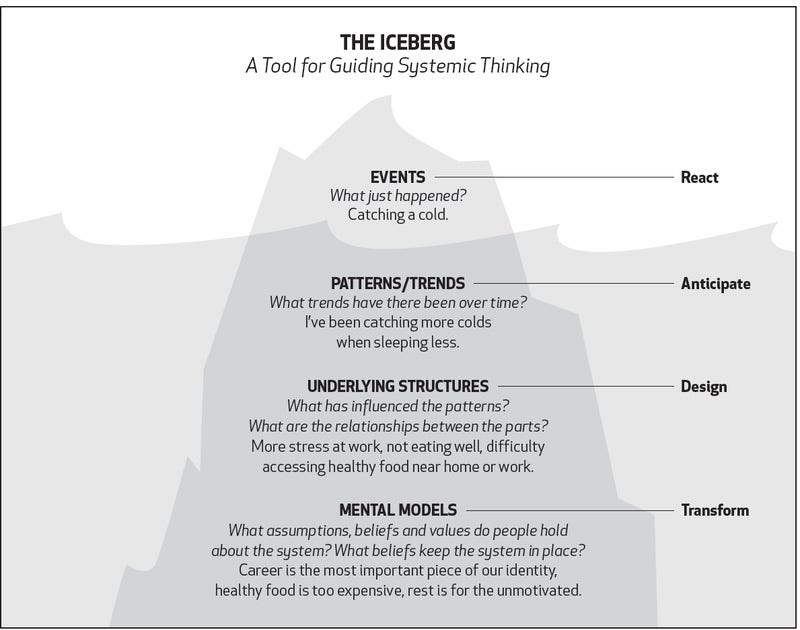
Levels of thinking in the iceberg model
1. The event level
At the tip of the iceberg are the events — the immediate issues that catch our attention. These are surface-level incidents that often demand urgent responses. Examples include:
- A critical system outage causes downtime.
- A major customer complains due to a missed project deadline.
- An unexpected defect is discovered in a recently released product.
While addressing these events is necessary, focusing solely on them keeps us in a cycle of reaction without addressing the root causes. It’s like repeatedly putting out fires without investigating what started them.
2. The pattern level
Just below the surface, patterns emerge when we observe similar events happening over time. Recognizing these patterns helps us anticipate issues. Examples of patterns might be:
- Frequent system outages: noticing that system downtimes occur consistently during peak traffic hours.
- Recurring customer complaints: observing that customer dissatisfaction spikes whenever a specific feature is updated.
- Consistent project delays: realizing that projects often overrun their deadlines by similar timeframes.
By identifying patterns, we begin to see that events are not isolated incidents but symptoms of deeper issues that need to be addressed.
3. The structure level
Deeper still are the structures influencing the patterns we observe. Structures include processes, organizational hierarchies, tools, and policies that shape behavior. Examples of structural issues might be:
- Inefficient resource allocation: teams are understaffed during critical periods, leading to burnout and mistakes.
- Outdated processes: reliance on manual testing rather than automated testing increases the chance of defects slipping through.
- Communication silos: departments not sharing information effectively, causing misalignment and delays.
These structures create the conditions that lead to the patterns and events we experience. By examining and modifying structures, we can influence the patterns and prevent undesirable events.
4. The mental model level
At the base of the iceberg lie the mental models — the beliefs, values, and assumptions that drive behavior within the system. Examples include:
- A speed over quality mindset: believing that getting products to market quickly is more important than ensuring they are free of flaws.
- Resistance to change: assuming that established processes don’t need updating because “they’ve always worked before.”
- Underestimating the importance of communication: not valuing cross-department collaboration, leading to isolated teams.
These underlying mental models perpetuate the structures and patterns leading to recurring events. Changing mental models can be challenging but is essential for sustainable transformation.
Strategies for implementing systems thinking
With a clear understanding of the underlying issues, the next step is to implement strategies that foster systems thinking and build self-sustaining processes. Here are actionable steps you can take to apply these strategies in your organization.
Engage your team in analysis
Involving your team in analyzing the different levels of the iceberg model is crucial. Suppose your team is experiencing frequent project delays. Organize a retrospective meeting involving project managers, engineers, and other stakeholders to examine each level:
- Events: document specific instances of delays and their immediate impacts.
- Patterns: collect data on project timelines to identify common bottlenecks.
- Structures: examine whether current project management tools and processes are effective.
- Mental models: encourage team members to share their beliefs about deadlines, workload management, and quality standards.
By bringing together diverse perspectives, you can uncover hidden issues and foster a sense of ownership over the solutions. This collaborative approach ensures that any changes made are well-informed and more likely to be embraced by the team.
Identify leverage points
Focus on areas where small, strategic changes can have a significant impact. Leverage points often exist within processes, resource allocation, or communication channels. For example:
- Implement a tiered support system: if customer complaints often arise due to slow response times from support, introduce first-line support for quick resolutions and escalate complex issues to specialized teams.
- Streamline approval processes: if project delays are the product of lengthy approval procedures, simplify or automate approvals to speed up workflow.
- Reallocate resources: if a team is consistently overloaded, redistribute tasks or hire additional staff to alleviate pressure and improve efficiency.
By targeting these leverage points, you can disrupt negative patterns and foster positive outcomes with relatively minimal effort.
Challenge mental models
Addressing and reshaping underlying beliefs is crucial for sustainable change. If there’s a “speed over quality” mindset leading to product defects:
- Initiate a cultural shift: launch training sessions emphasizing the importance of quality and its long-term benefits. Share case studies where poor quality led to significant issues.
- Promote open communication: if resistance to change stems from fear of the unknown, encourage transparency by involving team members in decision-making processes and explaining the benefits of new initiatives.
- Encourage cross-functional collaboration: if departments work in silos, organize joint projects or team-building activities to break down barriers and foster a collaborative culture.
Changing mental models may require consistent effort, but it lays the foundation for lasting improvement.
Develop an action plan
An action plan turns insights gained from discussions into concrete steps you can follow to improve the situation. For optimizing cross-department collaboration:
- Set clear objectives: aim to reduce project delays by 25% in the next quarter.
- Define actions: implement regular inter-departmental meetings, use collaborative tools like shared project boards, and establish clear communication protocols.
- Assign responsibilities: designate team leads to oversee collaboration efforts and ensure accountability.
- Set timelines: roll out changes within the next month and schedule regular reviews to assess progress.
An effective action plan should be specific, measurable, achievable, relevant, and time-bound (SMART) to ensure accountability and track progress.
Monitor progress and adjust
Continuous monitoring allows you to measure the effectiveness of changes and remain flexible. After implementing new processes:
- Track metrics: monitor KPIs such as customer satisfaction scores, defect rates, or project completion times. When metrics aren’t trending in the desired direction, analyze root causes and adjust your approach — perhaps by reallocating resources, modifying processes, or revising timelines.
- Gather feedback: regularly solicit input from team members about what’s working and what’s not. Use this feedback to make targeted improvements, such as streamlining overcomplicated processes or providing additional support where teams are struggling.
- Celebrate successes: recognize improvements and milestones to maintain momentum and motivate the team.
By staying attentive to results and being willing to adapt, you can ensure that the changes have a lasting positive impact.
Components of self-sustaining systems
Ensuring that all essential components are addressed will help build systems that are not only effective but also self-sustaining. Here are key elements to focus on:
1. Roles and responsibilities
Establishing clear organizational structure and team interactions forms the foundation of effective systems. While no longer current practice at Spotify, Henrik Kniberg’s influential 2012 model of scaling agile organizations demonstrates this through several key concepts.
The model organizes autonomous, cross-functional squads that operate like mini-startups, each owning a specific part of the product lifecycle. It scales collaboration through tribes — collections of squads working in related areas — to maintain coordination without sacrificing autonomy.
The model also builds expertise through chapters, where specialists across different squads share knowledge and practices. This structure exemplifies how clear roles and responsibilities can create self-sustaining systems that balance autonomy with collaboration.
2. Knowledge and skills
Developing a learning culture enables organizations to adapt and innovate continuously. Microsoft’s transformation under Satya Nadella, chronicled in his 2017 book “Hit Refresh,” showcases how even large enterprises can fundamentally reshape their culture:
The company focused on embedding a growth mindset where learning from failures is valued over knowing all the answers. This started with leaders modeling vulnerability by openly sharing their own failures and lessons learned. They implemented “failure retrospectives,” where teams analyzed setbacks not as problems to avoid but as valuable learning opportunities. Recognition systems were revised to reward innovative attempts and learning processes, not just successful outcomes.
They worked on breaking down silos by promoting cross-functional skill development and collaborative learning. This included rotating team members across departments, creating mixed-skill project teams, and establishing regular knowledge-sharing sessions where different departments teach each other about their work. They also implemented shared objectives that required multiple departments to collaborate, moving away from department-specific goals that encouraged isolation.
Microsoft also prioritized psychological safety which encouraged questioning, learning, and challenging the status quo. Leaders achieved this by actively soliciting diverse viewpoints in meetings, responding positively to challenges of their own ideas, and establishing “no-blame” policies for raising concerns. They created formal channels for anonymous feedback and suggestions, while also training managers to respond constructively to new ideas and concerns. Regular town halls and open forums were established where employees at all levels could question existing practices and propose alternatives without fear of negative consequences.
3. Processes and rituals
Establishing consistent operational practices ensures reliability and enables innovation. Drawing from their extensive experience operating large-scale systems, Google’s Site Reliability Engineering teams have pioneered practices that demonstrate this.
Their teams implement error budgets — a concept that gives teams a specific allowance for acceptable system failures. They define clear service level objectives (SLOs) that ensure technical decisions directly connect to customer impact.
Their teams also follow a structured post-incident analysis process that goes beyond just fixing immediate problems. Each incident triggers a formal review with a standardized template covering what happened, why it happened, its impact, and the broader systematic improvements needed. This systematic approach has helped Google build institutional memory and continuously improve their operational practices
Building and maintaining the right tooling infrastructure enables teams to work effectively. Netflix’s engineering organization, renowned for its open-source contributions and innovative practices, demonstrates this through several groundbreaking approaches.
Netflix pioneered chaos engineering through tools like Chaos Monkey, which randomly terminates instances in production to ensure systems can handle unexpected failures. This tool simulates real-world failures by deliberately causing outages during business hours when engineers are available to respond. This forces teams to build resilient systems that can handle failures gracefully. Netflix has built deployment pipelines that automate the process of moving code from development to production. These pipelines include automated testing, security scanning, canary deployments (rolling out changes to a small subset of users first), and one-click rollbacks if issues are detected.
For custom testing tools, Netflix developed and open-sourced several frameworks that others can learn from. The failure injection testing (FIT) framework allows teams to inject failures at the application level rather than the infrastructure level. For organizations looking to develop their own testing tools, Netflix’s engineering blog provides examples of their approach to testing distributed systems..
5. Observability and metrics
Creating comprehensive system visibility enables data-driven operations. AWS’s Well-Architected Framework, demonstrates effective observability through several key practices that have transformed how organizations monitor and respond to system behavior.
AWS implements integrated metrics, logging, and tracing that work together to provide complete system visibility. For example, when a customer experiences a slow checkout process, teams can trace the entire transaction path across different services, examine detailed logs of each component’s behavior, and correlate this with system-wide performance metrics. This three-pronged approach helps quickly identify whether the issue stems from database performance, network latency, or application code.
AWS aligns technical metrics directly with business outcomes through what they call “business-aware monitoring.” Rather than just tracking technical metrics like CPU usage or memory consumption, they monitor business-relevant metrics like order completion rate, revenue per hour, or customer engagement scores. When technical issues occur, teams can immediately see the business impact — for example, how a slight increase in API latency directly correlates to a drop in successful checkouts or customer engagement. This approach helps teams prioritize their responses based on actual business impact rather than just technical severity.
Implementing a performance management system fosters a culture of accountability and continuous improvement. Netflix’s widely studied high-performance culture, recently reaffirmed in their 2024 culture memo, demonstrates this.
Netflix hires experienced professionals who thrive in environments of freedom and responsibility, paying top-of-market compensation to attract and retain exceptional talent. To prevent burnout, they implement unlimited vacation policies and encourage actual usage, maintain flexible working arrangements, and explicitly discourage long hours. Instead of measuring time spent, they focus on impact delivered. Teams are kept intentionally lean, with each member bringing significant expertise and value, rather than distributing work across larger groups.
The company’s “keeper test” is a fundamental part of their performance management approach. Managers regularly ask themselves: “If this person were interviewing elsewhere, would I fight hard to keep them?” This isn’t about constant pressure, but rather about maintaining honest dialogue about performance and fit. If the answer is “no,” they provide generous severance packages rather than maintaining ongoing employment.
Netflix’s approach focuses on providing context rather than top-down control. In practice, this means leaders spend significant time sharing detailed information about company strategy, market conditions, and business challenges. For example, instead of dictating specific technical solutions, leaders might share comprehensive data about customer behavior, cost constraints, and strategic priorities, then trust their teams to make informed decisions.
Final thoughts
Picture this: Your phone buzzes with another escalation. But this time is different. Instead of jumping into firefighter mode, you see an opportunity for fireproofing.
Take that production incident, customer escalation, or team bottleneck and ask:
- What patterns made this inevitable?
- Which structures allow these patterns to persist?
- What system could prevent this entirely?
Then build it. While others scramble from crisis to crisis, you’ll be methodically eliminating the conditions that create them.
This article was originally published on LeadDev.com on Dec 24th, 2024.
15 Oct 2024
What a year in the trenches building with LLMs taught me about delivering value with AI
Artificial intelligence (AI) is rapidly becoming an integral part of modern engineering. From automating mundane tasks to driving groundbreaking innovations, AI offers unprecedented opportunities for organizations to gain a competitive edge.
I’ve spent over a year in the trenches building with LLMs and even longer working with applied ML. My company has shipped nearly 100 AI agents into production for our healthcare customers, achieving a 95% reduction in operational expenses and a 140% boost in staff productivity. We were able to achieve this by identifying the areas where AI could create the most value for our customers, pinpointing high-value opportunities.
Identify areas of impact
To maximize impact when building your AI roadmap, focus on areas where AI can truly move the needle for your customers and your business. Consider using a structured framework to systematically identify high-impact areas and prioritize AI opportunities based on customer needs, business value, and technical feasibility. This approach ensures your AI roadmap focuses on high-impact projects that align with your strategic objectives and timelines.
Start with projects that have clear ROI and potential for quick wins to build momentum for your AI initiatives and demonstrate value to your customers.
I recommend focusing on the following key areas where AI can deliver a significant impact:
Providing creative AI value
Developing AI systems that can generate content or solutions customers can’t easily create on their own is a great way to provide value to them.
Potential implementations include:
-
AI that generates code snippets, creates artwork, or writes marketing copy based on simple prompts
-
Content creation tools that produce reports, articles, or product descriptions
-
AI assistants that draft emails, create presentations, or generate data visualizations
These tools significantly boost your customers’ output and creativity, allowing them to produce high-quality work faster and more efficiently.
Using AI to curate, synthesize, and surface relevant information from vast datasets can improve customer decision-making and reduce time spent searching for information.
Potential implementations include:
-
AI-powered knowledge management systems that extract key insights from large documents or databases
-
Personalized insights that keep customers informed about trends, updates, or relevant news based on their data
-
Search systems that integrate traditional keyword search with AI-powered semantic search using embeddings to deliver highly relevant results
Improve process efficiency
Automating procedural tasks capable of independent action and decision-making within defined parameters frees up customer time to focus on higher-value activities.
Potential implementations include:
-
Advanced AI chatbots that handle complex customer inquiries, process orders, or provide technical support without human intervention
-
AI agents that perform automated quality checks on customer data or products
-
AI-driven systems for optimizing customer supply chains or scheduling resources
Combine intelligence for complex scenarios
Combine human and artificial intelligence to enhance your customers’ decision-making and problem-solving capabilities in complex scenarios.
Potential implementations include:
-
Co-pilot systems that work alongside customers in sophisticated tasks
-
AI assistants that help analyze large datasets, generate reports, or troubleshoot complex issues
-
AI systems that can suggest optimizations in manufacturing processes or supply chain management
These augmented intelligence initiatives leverage the strengths of both humans and AI, leading to superior outcomes for your customers in complex tasks.
Understand patterns of implementation
As you identify areas where AI can make a significant impact, it’s crucial to understand the high-level implementation patterns that can guide your roadmap. Recognizing these patterns helps in selecting the right approach for your specific needs, ensuring efficient resource allocation and maximizing the value delivered.
Here are the primary patterns to consider when building your AI roadmap:
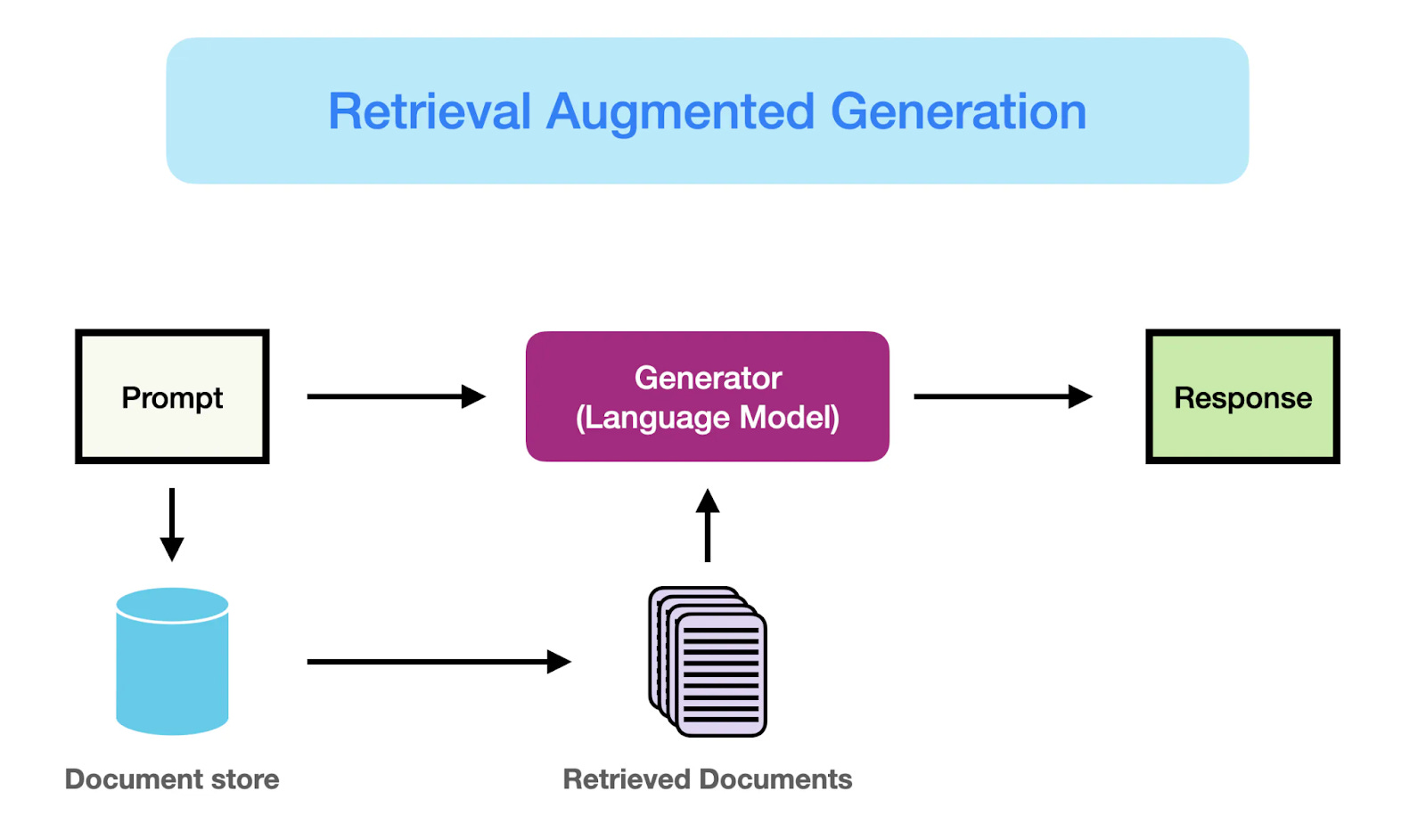
Retrieval-Augmented Generation (RAG)
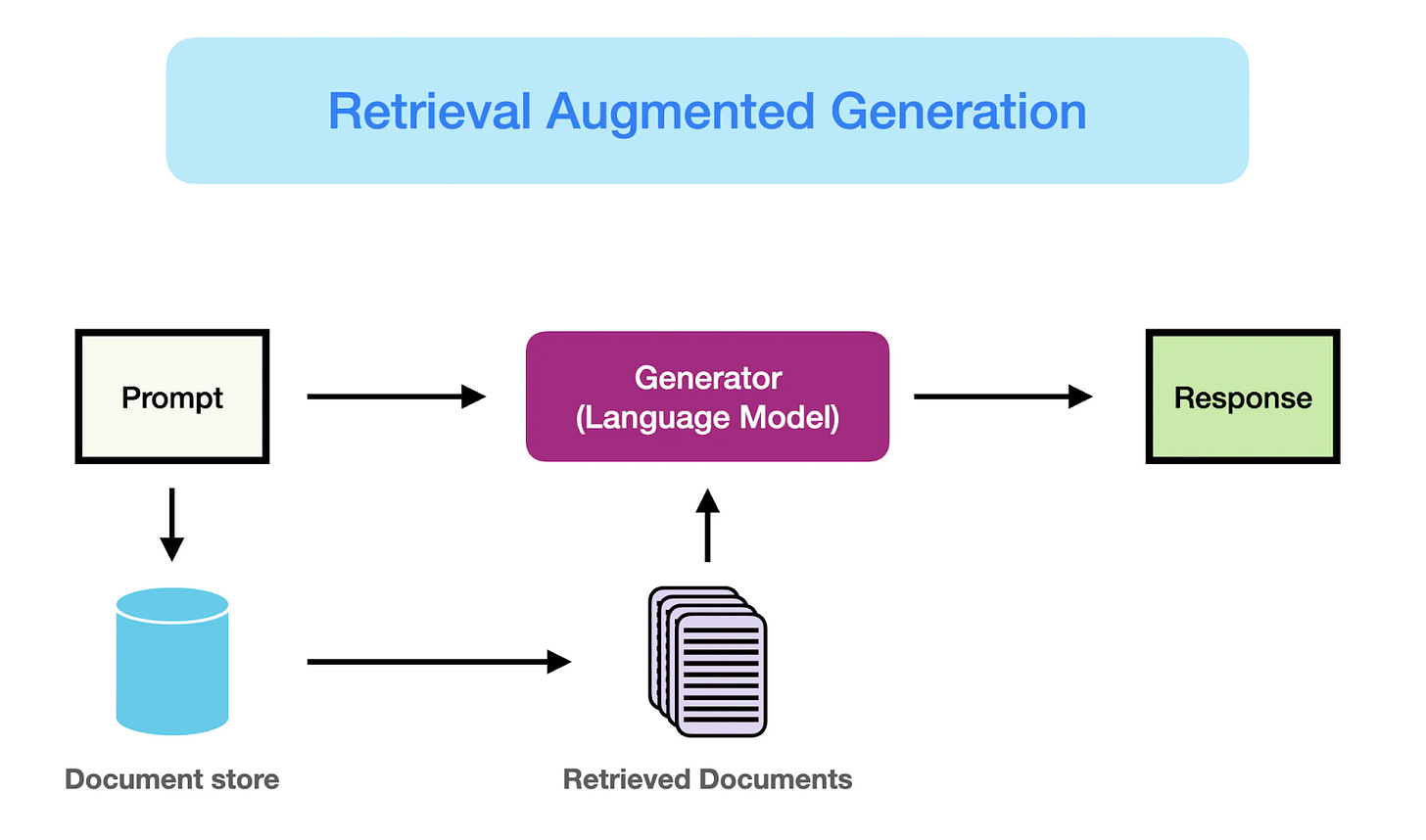
| (Source: [Retrieval Augmented Generation (RAG) for LLMs |
Prompt Engineering Guide](https://www.promptingguide.ai/research/rag)) |
RAG is a pattern that combines the capabilities of large language models (LLMs) with search functionalities. It involves retrieving relevant information from your data sources and using it to generate more accurate and contextually appropriate responses.
If your goal is to enhance information retrieval, provide detailed answers to user queries, or generate content based on specific data, RAG is an effective approach. For example:
-
Customer Support: Improving response accuracy by providing agents with relevant information drawn from internal knowledge bases.
-
Content Generation: Creating personalized reports or summaries by retrieving and synthesizing data from various sources.
Implementing RAG can be facilitated by tools like vector databases for efficient search and frameworks that integrate retrieval with LLMs.
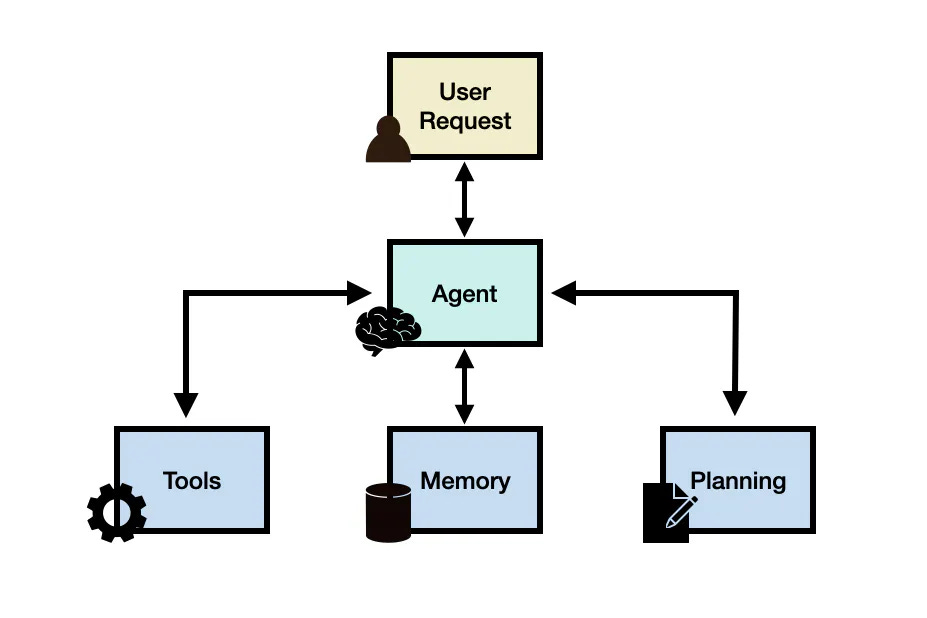
AI Agents
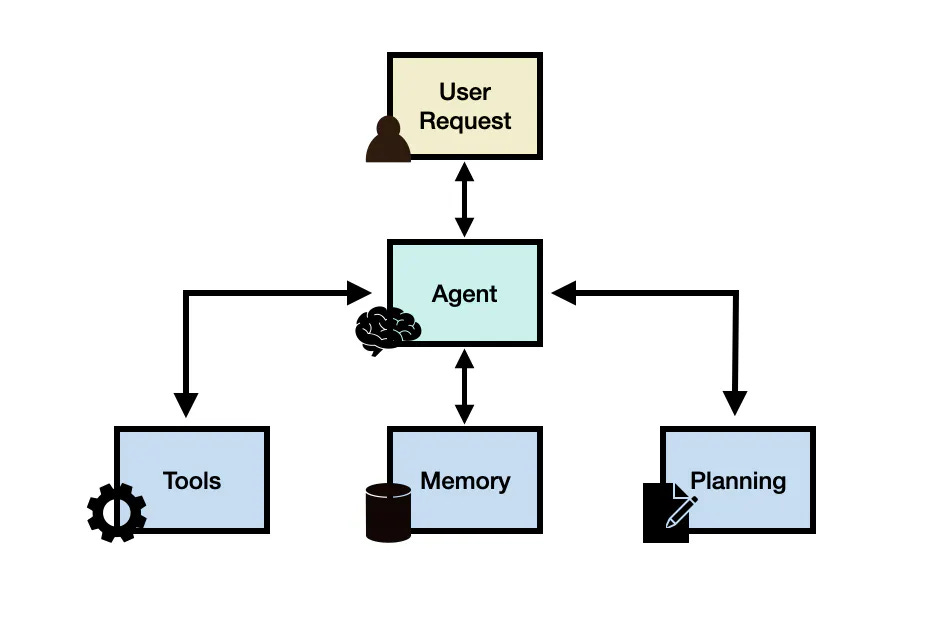
| (Source: [LLM Agents |
Prompt Engineering Guide](https://www.promptingguide.ai/research/llm-agents)) |
AI agents are systems that can perform tasks autonomously by making decisions and executing actions based on predefined objectives and real-time data. They can handle both attended tasks (requiring human oversight) and unattended tasks (operating independently).
For initiatives aimed at workflow optimization, process automation, or complex decision-making, AI agents are the go-to pattern. They excel in scenarios like:
-
Workflow Automation: Streamlining operations by automating routine tasks, freeing up staff to focus on higher-value activities.
-
Decision Support: Assisting in complex problem-solving by analyzing data and providing recommendations.
Building AI agents may involve using platforms that support agent orchestration, integration with various data sources, and capabilities for monitoring and adjusting agent behavior.
Hybrid Approaches
Sometimes, combining patterns like RAG and AI agents yields the best results. This hybrid approach leverages the strengths of both patterns to address more complex challenges.
In cases where you need both advanced information retrieval and autonomous task execution a hybrid approach is beneficial. For example:
- Code Generation: Developing tools that not only generate code snippets based on user prompts (utilizing RAG) but also test and implement code changes autonomously (leveraging AI agents).
Rapidly deliver value
It’s crucial to quickly demonstrate the value of your AI initiatives to your stakeholders and customers by following these guiding principles:
Start simple
When implementing AI solutions, simplicity is key to providing immediate value without unnecessary delays or costs. Here’s how you can achieve this:
-
Leverage existing APIs: find the quickest and easiest way to integrate LLM capabilities into your application by looking into readily available inference APIs from providers like OpenAI (GPT models) or Anthropic (Claude models). This approach allows you to offer advanced features to your customers quickly, without the time and expense of developing and training models from scratch.
-
Prioritize product-market fit: focus on ensuring your AI solution meets a real customer need before scaling up. By validating product-market fit early, you avoid investing heavily in expensive infrastructure like GPUs for training or fine-tuning models that may not deliver the desired value.
-
Consider self-hosting strategically: while self-hosting AI models can offer benefits like enhanced data privacy and cost optimization at scale, it may slow down initial value delivery due to setup complexity. Start with third-party services to provide immediate value, and consider self-hosting later as your needs for control and optimization grow.
Build, measure, and learn
After initiating your AI projects with simple implementations, it’s crucial to adopt an iterative approach to refine and improve your solutions. This cycle of building, measuring, and learning ensures that your AI initiatives continue to deliver increasing value over time. Here’s how to integrate this mindset:
-
Understand model benchmarks: use established benchmarks to help you pick the right model for the right job. For example, MMLU assesses models across 57 diverse subjects to gauge general knowledge and reasoning abilities, while SWE-Bench evaluates models on software engineering tasks, helping you understand their capabilities in coding and development contexts. By evaluating models against these benchmarks, you can select the most suitable model for your specific needs, ensuring a solid foundation for your project.
-
Start with unit tests: develop tests or system evaluations that are specific to your application. These evaluations aim to validate functionality, catch regressions, and ensure your AI system performs optimally for your particular use case. Checking your AI system using real examples to ensure it works correctly. Provide sample inputs that reflect how users will interact with your system and verify that the outputs are appropriate. This helps you quickly spot any issues and make sure your AI solution meets basic requirements.
-
Embrace LLMOps: LLMOps (Large Language Model Operations) refers to the practices and tools used to manage, deploy, and maintain large language models effectively in production environments. Instead of building these tools in-house – which may become commoditized – leverage existing solutions for observability and monitoring, such as LangSmith and Langfuse. This allows you to focus on production monitoring and continual enhancement, responding promptly to issues, and adapting your AI systems based on real-world usage.
Manage expectations
As you transition from proof-of-concept to production, it’s crucial to manage the expectations of all stakeholders – including users, team members, and leadership – to build trust in your AI-powered systems. Proper expectation management ensures that everyone understands the capabilities and limitations of your AI solutions, which is essential for delivering consistent value.
-
Ensure accuracy and reliability: users need to trust that your AI systems are providing accurate and reliable information. Be transparent about your system’s limitations, but if you find your model is underperforming, explore techniques like retrieval-augmented generation (RAG) to provide more context, or fine-tune your model.
-
Design a defensive UX: create user interfaces that clearly communicate the AI system’s capabilities, limitations, and confidence levels. Provide explanations for AI-generated outputs where possible and incorporate user feedback mechanisms that allow users to report inaccuracies
-
Implement escape hatches: plan for situations where AI may not provide satisfactory solutions by implementing “escape hatches” and human-in-the-loop processes. This could involve a tiered response system where AI handles simple queries while complex issues are flagged for human review.
Prepare for the future
While delivering immediate value is essential, it’s equally important to design your AI initiatives with the future in mind. By anticipating changes and building adaptability into your systems, you ensure that the value you deliver today can be sustained and enhanced over time. Here’s how:
-
Decreasing costs: as hardware becomes cheaper and more efficient, and as open-source models become more accessible, you can scale your AI solutions without significant additional investment. This allows you to offer more value to your customers quickly, as you can reinvest savings into new features or pass them on to customers.
-
Evolving technology: anticipate that today’s cutting-edge AI research will become commoditized in the future. Stay ahead of the curve by integrating these advancements early to deliver innovative solutions now, but avoid heavily investing in building everything in-house. Instead, leverage existing technologies and be prepared to adopt commoditized versions as they become available. This approach lets you capitalize on the latest innovations without getting locked into costly, custom-built systems, enabling you to maintain agility and continue delivering value rapidly.
-
Flexible architecture: design your systems to be adaptable, ensuring you can easily swap out underlying components like the LLM or vector store as newer and better alternatives emerge. This flexibility allows you to quickly implement improvements without overhauling your entire system, enabling you to deliver enhanced value to your customers promptly.
Close the talent gap
The rapid rise of AI has created a significant demand for skilled AI engineers and data scientists. Building an AI-ready team requires a multi-pronged approach.
Hiring applied AI talent
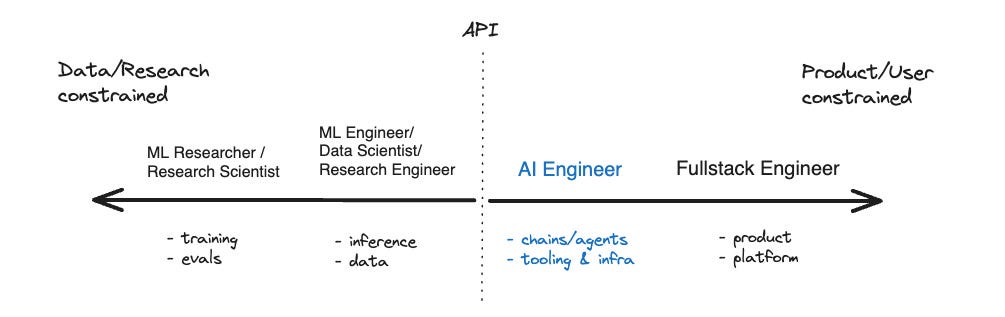
When hiring for AI talent, it’s crucial to understand the distinction between research and applied AI engineering. Researchers focus on pushing the boundaries of AI, developing new algorithms, and publishing academic papers. Applied AI engineers, on the other hand, focus on taking those advancements and translating them into real-world products. They are the bridge between cutting-edge research and practical implementation.
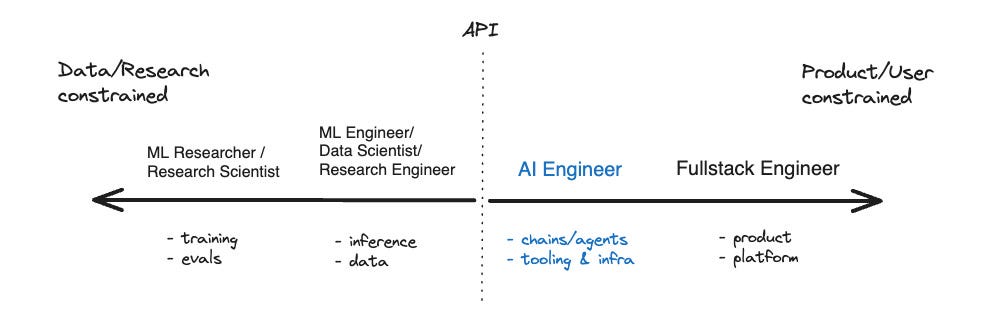
(Source: The Rise of the AI Engineer - by swyx & Alessio)
What to look for in candidates
When evaluating candidates for AI engineering roles, prioritize the skills that enable them to build and ship AI-powered products.
The Rise of the AI Engineer emphasizes the importance of strong software engineering skills. Look for proficiency in languages like Python and JavaScript, experience with software development best practices, a deep understanding of data structures and algorithms, and a knack for building scalable and maintainable systems.
While theoretical knowledge is valuable, prioritize candidates with hands-on experience using popular AI tools and frameworks. This includes familiarity with:
-
LLM APIs: experience working with APIs from providers like OpenAI and Anthropic to integrate pre-trained models into applications.
-
Chaining and retrieval Tools: knowledge of tools like LangChain and LlamaIndex for building complex LLM workflows and integrating external data sources.
-
Vector databases: experience with vector databases like Pinecone and Weaviate for efficient semantic search and retrieval.
-
Prompt engineering techniques: A strong understanding of prompt engineering principles and the ability to craft effective prompts to elicit desired responses from LLMs.
Seek candidates who are passionate about building products and solving real-world problems with AI. Look for a demonstrated ability to translate AI concepts into tangible user benefits.
Lastly, prioritize candidates who are adaptable, eager to learn new technologies, and can keep pace with the latest advancements in the field.
By focusing on these practical, product-oriented skills, you can build a high-performing AI team capable of delivering real value to your organization.
Upskill your existing engineers
As AI becomes increasingly integrated into various aspects of software development, the lines between “AI engineering” and “software engineering” will blur.
It’s important to cultivate a basic understanding of AI concepts and principles across your entire engineering team, empowering everyone to contribute to the success of your AI initiatives.
Provide opportunities for your current engineers to upskill and learn AI concepts and tools.
Use workshops and hackathons as learning devices
To help upskill the talent you already have, organize hands-on workshops and hackathons focused on AI. Bring in external AI experts or leverage internal knowledge to lead these events, focusing on real-world applications relevant to your business.
Encourage cross-functional teams to tackle actual business problems using AI during hackathons, providing valuable learning experiences and the potential to accelerate the AI roadmap. By showcasing successful projects company-wide, you can inspire and motivate other team members to engage with AI technologies.
Rotation and hands-on experience for upskilling
Regularly cycle team members through AI-focused projects or teams, allowing them to gain hands-on experience with various AI applications.
This rotation program serves multiple purposes: it provides practical, real-world experience with AI technologies, exposes engineers to different use cases and challenges, and helps disseminate AI knowledge throughout your organization.
As engineers work on diverse AI projects, they’ll naturally build a broader skill set and a deeper understanding of how AI can be applied to solve business problems. Moreover, this rotation strategy can help identify hidden talents and interests among your engineers, potentially uncovering AI champions who can further drive innovation in your organization.
Final thoughts
Building and executing an effective AI roadmap is an ongoing journey that requires careful planning, experimentation, and adaptation. By embracing a structured approach, prioritizing practical implementation, and remaining adaptable to the ever-evolving AI landscape, engineering leaders can successfully navigate the challenges and opportunities of AI adoption, leading their teams and organizations toward a brighter, AI-powered future.
This article was originally published on LeadDev.com on Oct 14th, 2024.
31 Jul 2024
The current job market is overflowing with competition, put yourself in better stead for meeting the job spec by asking yourself these 6 questions before applying.

Rejection stings. As engineers, we’re wired to solve problems and achieve goals. In today’s job market, it can be tricky to get past the first stage, let alone a second or third, so a “no” can feel like a personal setback. But what if we could reframe potential rejection as a learning opportunity before it even happens?
Enter the premortem, a tool used in project management to anticipate potential failures before they occur. Applying the concept of premortems to your job search and anticipating what might cause your application to be rejected, can help you navigate the process more effectively. Here are six questions to ask yourself before applying to better align with the job spec.
1. Does my expertise match the demands of the company’s size?
Knowing the type of environment you thrive in and applying that to your search is an important step. Different company settings require different skill sets and experiences, so a mismatch in company size or stage can lead to difficulties in adapting to the pace.
For example, if you’ve spent the last five years at Google working on large-scale infrastructure projects, moving to a 10-person start-up might require you to wear multiple hats and work on tasks outside your current expertise. Conversely, someone used to the fast-paced, multifaceted nature of a start-up might struggle with the bureaucratic processes in a large corporation.
Action:
-
Create two versions of your resume: one tailored for smaller companies and another for larger organizations.
-
List three to five specific projects or experiences that demonstrate your adaptability to different company sizes.
-
Draft a paragraph for your cover letter explicitly addressing your fit for the company’s size.
2. Can I effectively integrate into this team structure and working style?
Look into the team and wider org structure of the company you’re applying to and consider whether your skill set lends itself to the internal dynamics. Reflect on your collaboration style; do you prefer working as part of a specialized team or within a cross-functional one?
For example, if you’re a machine learning specialist within a dedicated research team, transitioning to a product-focused team where you need to collaborate closely with UX designers, product managers, and software engineers might be challenging. You may need to adapt your communication style by simplifying technical jargon, learning to translate complex concepts for non-technical team members, and developing skills in areas like product management or user experience to contribute effectively.
Conversely, if you’re accustomed to working in a cross-functional product team and plan to join a specialized research group, you might struggle to dive deep into a specific area of expertise and adapt to a more focused, research-oriented workflow.
Action:
-
Research the company’s team structure (e.g., cross-functional, specialized) using their website or job description.
-
Prepare two to three specific examples of how you’ve successfully adapted to different team structures in the past.
-
List questions to ask during the interview about team dynamics and collaboration methods.
3. Does my area of expertise directly address the challenges and goals of this particular role?
Having the right skills doesn’t guarantee you’re the right fit for the team’s needs. It’s crucial to ensure that your expertise aligns with the specific requirements of the role you’re applying for. This goes beyond just matching keywords on a job description; it involves understanding the nuances of the role, the team’s current challenges, and the company’s strategic goals.
Consider the depth and breadth of your expertise in relation to the role’s demands. Some positions may require deep specialization in a particular area, while others might value a broader skill set. Additionally, the team may be looking for someone to fill a specific gap or bring a particular perspective that complements existing team members’ skills.
It’s also important to consider the trajectory of your career and how it aligns with the role’s growth potential. A position that doesn’t allow you to utilize your core strengths or develop in your desired direction might not be the best fit, even if you have the required skills on paper.
For example, you might be applying for a full-stack role, but if the team is looking for more back-end expertise and your strength lies primarily in front-end development, this could be a misalignment. Despite your full-stack development experience, your limited depth of experience on the server side could be a dealbreaker for the hiring team if they’re specifically looking to bolster their back-end capabilities.
Alternatively, if you’re a generalist full-stack developer applying to a role that requires deep specialization in a particular area like database optimization or scalability, your breadth of knowledge might not compensate for the lack of in-depth expertise they’re seeking.
Action:
-
Create a table mapping your skills to the job requirements, identifying any gaps.
-
Choose three key skills from the job description and write a brief statement for each, explaining how you’ve applied them in past roles.
-
Identify any areas where you may lack experience and prepare talking points about how you will mitigate the skill gap.
4. Have I researched the demands of this industry?
If you’re transitioning to a new industry altogether, you may have some other facets to consider before hitting “send” on your CV. Moving fields will involve adapting to different regulations, stakeholder expectations, and industry-specific knowledge. This can present a steep learning curve, so you have to be sure you’re well-equipped to walk into this role.
To capitalize on transferable skills, identify core competencies from your current role that are valuable across industries. These might include project management, data analysis, problem-solving, or leadership skills. Then, frame these skills in the context of the new industry.
For instance, if you’ve managed tech projects in the software industry and are transitioning to healthcare, you could highlight:
-
Project management: Emphasize how your experience managing complex software projects can translate to overseeing the implementation of healthcare IT systems.
-
Stakeholder communication: Showcase how your ability to communicate technical concepts to non-technical stakeholders can be applied when explaining medical technologies to healthcare professionals.
-
Regulatory compliance: If you’ve dealt with data privacy in tech, highlight how this experience can be valuable in understanding and implementing HIPAA compliance in healthcare.
-
Problem-solving: Illustrate how your approach to troubleshooting software issues can be applied to optimizing patient care workflows.
At the very least, anticipate questions from the hiring team about your industry transition and prepare examples that demonstrate how your transferable skills can add value in the new context. Be prepared to discuss how you plan to bridge any knowledge gaps and show enthusiasm for learning industry-specific regulations and practices.
Action:
-
Read industry-specific publications or reports to familiarize yourself with current trends and challenges.
-
Identify and list key trends, regulations, or standards relevant to the industry you’re targeting.
-
Connect with two to three professionals in the target industry via LinkedIn to network and learn more.
5. Do my values align with the company’s culture?
Finding a company that’s a good cultural fit is often as important as skills and experience. Misalignment with a company’s core values and culture can lead to dissatisfaction and a lack of fulfillment. Before you start applying for jobs, take some time to reflect on your own values, work style preferences, and what you consider to be an ideal work environment.
To pinpoint the cultural vibe of a company you’re applying to, consider the following:
-
Company website and social media: Look beyond the job description. Examine the company’s mission statement, values, and how they present themselves online. What values do they emphasize?
-
Employee reviews: Sites like Glassdoor can offer insights into the company culture from current and former employees. Look for patterns in the reviews.
-
News and press releases: These can give you an idea of the company’s priorities and how they handle various situations.
-
Interview process: Pay attention to how the company conducts its hiring process. Is it efficient and respectful of your time? This can be indicative of their overall organizational culture.
-
Questions asked during interviews: Are they focused solely on technical skills, or do they also inquire about your work style, collaboration preferences, and career goals?
-
Office environment: If you have an on-site interview, observe the workspace. Is it open-plan or more traditional? How do employees interact?
-
Communication style: Notice how quickly the company responds to your emails and the tone of their communications. This can reflect their internal communication culture.
Action:
-
List the company’s stated values (usually found on their website) and write a brief example of how you’ve demonstrated each in your career.
-
Prepare three specific questions about company culture to ask during your interview.
-
Write down three of your own core values and be prepared to discuss how they align with the company’s culture.
6. How can I differentiate myself from other applicants?
In a competitive job market, it’s important to evaluate how your profile stacks up against other candidates. Highlighting your unique value proposition can make you a clearer frontrunner. Your unique value proposition is the combination of skills, experiences, and qualities that set you apart from other candidates and make you particularly well-suited for the role.
Remember, your unique value proposition isn’t just about being different; it’s about being different in a way that’s valuable to the employer. It should highlight not just what makes you unique, but why that uniqueness matters in the context of the job you’re applying for.
For example, if you’re applying for a data scientist position at a competitive tech company, you might be up against candidates with PhDs, extensive publications, and experience at leading firms. To stand out, you could highlight unique projects where you’ve driven significant business impact, your ability to communicate complex data insights to non-technical stakeholders, or any relevant interdisciplinary skills.
Action:
-
Write a one-paragraph, unique value proposition statement highlighting your distinctive skills and experiences.
-
Identify three quantifiable achievements from your career and frame them in terms of business impact.
-
Create a brief “elevator pitch” that succinctly communicates your unique qualifications for the role.
What happens in the face of rejection?
Remember, rejection is not a reflection of your worth as an engineer. It’s an opportunity to learn, adapt, and refine your approach. By incorporating both pre-mortem analysis and post-rejection reflection into your job search, you can turn setbacks into stepping stones for future success.
If faced with rejection, consider these steps for a thorough retrospective:
-
Request feedback: If possible, ask the hiring manager or recruiter for specific feedback on your application or interview performance.
-
Review your application: Assess whether your resume, cover letter, and portfolio (if applicable) effectively highlighted your most relevant skills and experiences.
-
Reflect on the interview process: Consider your performance in technical and behavioral interviews. Did you provide clear, concise examples that demonstrated your skills? Were there areas where you struggled?
-
Assess your preparation: Evaluate how well you researched the company and articulated your interest in the specific role.
-
Evaluate your unique value proposition: Did you effectively communicate what sets you apart from other candidates and connect your unique skills to the company’s needs?
-
Consider external factors: Acknowledge that sometimes rejections are due to factors beyond your control, but focus on what you can improve.
-
Develop an improvement plan: Based on your analysis, identify areas for improvement and set specific, actionable goals. For example, “I will improve my coding interview skills by completing one LeetCode challenge daily for 30 days” or “I will practice mock system design interviews weekly.”
-
Stay resilient: Maintain a growth mindset and view each application and interview as a learning experience. Keep your job search active and don’t put all your hopes on one opportunity.
By systematically reviewing your experience and making targeted improvements, you can enhance your candidacy for future opportunities. Remember, many successful professionals have faced rejection on their career paths. The key is to learn, adapt, and persist in your job search journey.
This article was originally published on LeadDev.com on Jul 30th, 2024.
03 May 2024
Manage the stresses of complex problem-solving, tight deadlines, and high-pressure situations at work with integrity and emotional intelligence.

A few years ago, I discovered Don Miguel Ruiz’s renowned book, The Four Agreements, which provides four simple yet profound principles for personal growth and self-improvement. Since then, I’ve found myself frequently applying its principles to navigate workplace challenges, such as communicating effectively with colleagues, managing stress and emotions during high-pressure situations, and maintaining integrity and authenticity in the face of difficult decisions.
Integrating these tenets into my daily professional life has been a powerful self-coaching tool, helping me handle common workplace pressures with calm composure.
What are the four agreements?
The four agreements are the following set of practical guidelines:
- Be impeccable with your word – Speak with integrity and honesty, avoiding gossip and self-deprecation. Use your words constructively.
- Don’t take anything personally – Recognize that others’ actions and opinions are projections of their own reality, not yours. Don’t let them needlessly affect you.
- Don’t make assumptions – Communicate clearly and ask questions to ensure mutual understanding. This helps prevent misinterpretations and conflicts.
- Always do your best – Your best may vary from moment to moment, but by always striving to do your best, you’ll avoid self-judgment and regret.
While these principles were developed for personal growth, they hold immense value in professional settings where clear communication, trust, and collaboration are crucial.
1. Be impeccable with your word
Clear and honest communication is the foundation of trust and reliability. Being impeccable with your word means making commitments you can keep, providing feedback that is both truthful and constructive, and ensuring that your communications uplift and empower your colleagues.
“I define integrity as honoring your word. A person with integrity keeps her promises whenever possible, and still honors them if she is unable to do so. You make a grounded promise by committing only to deliver what you believe you can deliver. You keep the promise by delivering it. And you can still honor the promise when you can’t keep it by letting the person you are promising know of the situation, and taking care of the consequences.”
― Fred Kofman, The Meaning Revolution: The Power of Transcendent Leadership
How to practically apply this principle:
-
Commitments: When discussing project timelines or deliverables with your manager or team, be clear and truthful about estimates and potential challenges. Follow through on your promise when you commit to a deadline or task. If circumstances change and you cannot meet the commitment, communicate promptly and transparently to manage expectations.
-
Feedback: When having tough conversations, such as providing critical feedback or addressing performance issues, speak with honesty and empathy, focusing on facts and constructive solutions rather than personal attacks or accusations.
Avoid participating in or spreading rumors about team dynamics or project decisions. Instead, encourage open and transparent communication using tools such as team surveys, decision logs, or requests for comments (RFCs) to surface feedback through the right channels.
-
Escalations: When direct communication with a colleague can’t resolve an issue, employ the concept of clean escalation. This involves presenting the problem to a higher authority or a mediator without undermining or blaming others. Approach escalation by clearly stating the facts, outlining your efforts to resolve the issue, and providing constructive suggestions for the next steps. This practice ensures issues are addressed with integrity, fostering a solution-oriented, respectful work environment.
-
Recognition: When acknowledging contributions or achievements, be genuine and specific in your praise, recognizing the efforts and impact of individuals or teams.
Mastering the art of communication is a transformative tool in any professional’s arsenal. Commit to maintaining high standards of integrity in all your interactions, which strengthens relationships and fosters a reliable and ethical work environment. For more techniques on how to become impeccable with your words, check out Fred Kofman’s courses on making commitments and managing conflict.
2. Don’t take anything personally
Feedback and critiques are part and parcel of the professional environment. They aim to improve quality and project outcomes, not diminish personal worth. Cultivating the ability not to take things personally can transform potentially defensive situations into opportunities for learning and growth.
“There’s several reasons why it makes sense to begin building a culture of radical candor by asking people to criticize you. First, it’s the best way to show that you are aware you are often wrong and that you want to hear about it when you are. You want to be challenged. Second, you’ll learn a lot. Few people scrutinize you as closely as do those that report to you. […] Third, the more first hand experience you have with how it feels to receive criticism, the better idea you’ll have of how your own guidance lands for others. Fourth, asking for criticism is a great way to build trust and strengthen your relationships.”
― Kim Malone Scott, Radical Candor: Be a Kickass Boss Without Losing Your Humanity
How to practically apply this principle:
-
Feedback: Establish a culture where giving and receiving feedback is seen as a natural part of the continuous improvement process, not a personal criticism.
-
Disagreements: When faced with disagreements or differing opinions, separate the ideas from the individuals. Focus on understanding the rationale behind different perspectives without taking the opposing views as a personal affront.
-
Failures: View project setbacks, bugs, or failures as learning opportunities rather than personal shortcomings. Approach them with curiosity and a growth mindset, seeking to understand the root causes and implement improvements.
-
Emotions: Recognize that emotions are a natural part of the human experience, but it’s essential to manage them effectively in professional settings. To separate your own emotions from work interactions, practice mindfulness by acknowledging your emotions without judgment and consciously redirecting your focus back to the task at hand. Use cognitive reframing to look at the situation from a different perspective and find a more objective or positive interpretation.
Not taking things personally is crucial for professional resilience and growth. Encourage a feedback-rich environment where all team members feel safe to express honest opinions. For additional strategies on building this type of environment, consider reading Kim Scott’s book on Radical Candor to learn techniques for getting, giving, and encouraging feedback and guidance that’s kind, clear, specific, and sincere.
3. Don’t make assumptions
Miscommunications can derail projects. By not making assumptions and seeking clarity, you prevent misunderstandings and ensure that everyone is aligned on project goals and methods.
“Seek first to understand, then to be understood. This principle is the key to effective interpersonal communication.”
― Stephen R. Covey, The 7 Habits of Highly Effective People
How to practically apply this principle:
-
Active listening: In any conversation or collaboration, practice active listening to fully understand the other person’s perspective, needs, and ideas. Give your full attention to the speaker, ask clarifying questions, and paraphrase their key points to confirm your understanding. By engaging in active listening, you demonstrate respect, build rapport, and gather the necessary information to make informed decisions and avoid misunderstandings.
-
Decision-making: When faced with important decisions, involve relevant stakeholders and gather diverse perspectives. Create opportunities for open discussion through meetings, collaborative documents (e.g., shared notes, wikis), surveys, and 1:1 conversations. Maintain a decision log to ensure transparency and accountability. By providing multiple avenues for input and collaboration, and keeping a record of the decision-making process, you can make informed decisions that consider diverse viewpoints.
-
Culture: In multicultural or global teams, be aware of potential cultural differences and avoid making assumptions about communication styles, work practices, or social norms. For example, some cultures may value direct communication, while others prefer a more indirect approach. Similarly, attitudes towards hierarchy, decision-making processes, and work-life balance can differ greatly between cultures. Approach interactions with curiosity and a willingness to learn.
-
Empathy: Before jumping to conclusions about a colleague’s behavior or actions, consider that you may be unaware of underlying factors or perspectives. Practice empathy and seek to understand their context before making assumptions.
Avoiding assumptions is fundamental to fostering clear and effective communication. As Stephen R. Covey advises, you can prevent many workplace misunderstandings and conflicts by actively seeking to understand before being understood. This habit aligns teams and supports a culture of open dialogue and mutual respect.
4. Always do your best
Your “best” can vary daily, but the commitment to give your all within your current circumstances fosters a culture of accountability and excellence. Demonstrating personal responsibility, openly communicating challenges, and learning from setbacks builds trust, psychological safety, and a shared commitment to learning and growth, rather than perfection. It reduces the guilt of not meeting unrealistic expectations and highlights the value of consistent effort over sporadic perfection.
“In the fixed mindset, everything is about the outcome. If you fail—or if you’re not the best—it’s all been wasted. The growth mindset allows people to value what they’re doing regardless of the outcome. They’re tackling problems, charting new courses, working on important issues. Maybe they haven’t found the cure for cancer, but the search was deeply meaningful.”
― Carol S. Dweck, Mindset: The New Psychology of Success
How to practically apply this principle:
-
Prioritization: In moments of high stress or tight deadlines, prioritize and give your best to the most critical tasks. Remember, “your best” doesn’t mean overworking but rather applying yourself effectively within the given constraints.
-
Learning: Embrace a growth mindset and continuously seek opportunities to expand your knowledge and skills. Attend workshops, read industry publications, or participate in professional development programs to enhance your abilities and stay current with best practices.
-
Balance: Recognize the importance of self-care. Make time for activities that rejuvenate you, such as exercise, hobbies, or spending time with loved ones. A well-rested and balanced individual is better equipped to do their best work.
-
Collaboration: Foster an environment of collaboration and support within your team. Offer assistance when colleagues need it, and don’t hesitate to ask for help when you need it. Collective effort and mutual support can help everyone perform at their best.
Strive for consistent effort rather than perfection, focusing on what can be learned from each experience. Embrace a growth mindset to foster an environment of continuous improvement. To build a practice of getting comfortable with setbacks and failures and learning from them, Carol Dweck’s Mindset is a must-read.
Closing thoughts
Integrating the four agreements into your professional life isn’t just about enhancing your work environment; it’s about cultivating a philosophy of personal and collective excellence. Reflect on these agreements regularly and strive to live by them, as they have the potential to fundamentally improve both your professional and personal life.
This article was originally published on LeadDev.com on April 24th, 2024.
06 Apr 2024

How can engineers ensure their skills keep up with AI advancements?
Over the last few years, we’ve watched AI take giant leaps in coding – from AI-assisted coding tools like GitHub Co-Pilot to the first AI engineer named Devin. This explosion of AI capabilities has sparked endless debates, with the burning question on everyone’s mind being: does software engineering still have a future?
The short answer? Yes, but with a catch. The coding aspect of software engineering might become more automated, with AI taking over the bulk of code generation in the future. However, software engineering is more than code.
Looking ahead, engineers who can zero in on business results, flex into other roles, and consistently deliver value will continue to be in demand despite AI as their impact extends beyond their coding ability.
Think like an entrepreneur
Simply being skilled in engineering won’t cut it anymore. The real magic happens when you connect engineering efforts directly to business outcomes. Embracing an entrepreneurial mindset equips engineers with a broad view that transcends the immediate technical challenges. In a world where AI can write code but cannot grasp the entire organization’s nuances, its people, culture, and the broader environment it operates within, having an expansive vision becomes a critical advantage.
Engineers who think like entrepreneurs understand that success in the AI era demands more than technical excellence. They have an intrinsic drive to create customer value, ensuring their engineering solutions are not just technically sound but also strategically aligned with business goals. They’re the bridge between technical feasibility and product strategy, using their skills to steer product decisions in the right direction.
How can you become an intrapreneur?
1. Understand the business
- Why? This will help you see where your projects fit within the larger picture and how they can influence the bottom line.
- How? Dive into your company’s OKRs and KPIs to understand the measures of success. Participate in all-hands meetings, review annual reports, do competitor research, and stay informed on company strategy.
2. Build customer empathy
- Why? Putting yourself in the customer’s shoes will help you make informed engineering decisions that resonate with user needs and business goals.
- How? Explore business intelligence (BI) tools, user experience (UX) research, and analytics platforms to understand customer sentiment and user behavior. Additionally, listen to recorded sales calls, if available, to get a first-hand pulse of what the customer is thinking and how they are reacting to the product.
3. Incorporate insights into decision-making
- Why? Combining business context and data-driven insights in your decision-making process ensures that your engineering efforts are both technically sound and strategically aligned with business objectives.
- How? When proposing new features or improvements, connect it back to the business objectives, user feedback, and data analysis that support your suggestion. Present your ideas in a way that highlights their potential impact on both user satisfaction and business success.
By embracing these practices, you will become adept at navigating uncertainty, prioritizing projects that offer the highest return on investment, and persuasively advocating for your ideas.
Flex across functions
Hand-in-hand with a business-centric approach is the need to wear multiple hats. The more versatile an engineer is, the more indispensable they become.
In a world where specific tasks may eventually be automated by AI, human engineers’ ability to synthesize information across domains, connect disparate ideas, and apply insights in new contexts sets them apart.
How can you cultivate versatility?
1. Collaborate on the product roadmap
- Why? Gaining insight into your company’s product goals and understanding how technology can drive these objectives is crucial as it broadens your perspective beyond just the technical aspects of your work.
- How? Volunteer to join roadmap planning sessions and offer a technical perspective on proposed features. Help with prioritization by assessing the technical effort required versus the projected business impact.
2. Contribute to design systems
- Why? Understanding design principles is crucial for creating technically sound products that provide a great user experience. A basic knowledge of UX/UI principles, color theory, and user-centric design can significantly improve the collaboration between engineering and design teams, leading to more cohesive and user-centric products.
- How? Work closely with designers to understand the core components of your product’s UI/UX. Offer to develop a shared library of UI components or a style guide that codifies design principles and patterns.
3. Mentor across functions
- Why? Sharing your expertise and insights across different functions not only helps others grow but also establishes trust, builds communication skills, and positions you as someone they can go to in the future.
- How? Initiate informal coffee chats or lunch meetings with peers in different roles. Offer mentorship or advice, focusing on how their roles contribute to the business’s success. This could involve guiding a designer on how to consider technical constraints in their designs or helping a marketing colleague understand the possibilities of the product.
By actively engaging in these practices, you’ll be well on your way to becoming a more versatile engineer. This cross-functional agility ensures that engineers can adapt to changes, foresee the implications of decisions across domains, and innovate at the intersections of disciplines, enabling them to provide value that no AI point solution can.
Carve your niche
Grounded in a rich understanding of the broader context and enhanced by a diverse skill set, building specialization will ensure that engineers can bring unique insights, creativity, and solutions that AI cannot. It’s the intersection of depth and breadth in an engineer’s expertise that will define their irreplaceability in an AI-driven world.
This is where Roger Martin’s Doctrine of Relentless Utility comes into play, a career strategy that focuses on finding your niche and monopolizing it.
As you become more adept at navigating between different roles and perspectives, you’ll be better positioned to uncover unique opportunities where your particular blend of skills and interests intersect with unmet needs within your team or organization.
Aligning what you’re good at with areas where you can make a significant impact allows you to establish a distinctive role that plays to your strengths and passions. This strategy promotes an active, value-driven approach, looking for ways to contribute beyond the usual scope of your role.
For instance, let’s say you have a knack for simplifying complex technical concepts into digestible content. Your niche could be bridging the gap between advanced technical knowledge and non-technical stakeholders or clients. Build on this by developing and sharing insights through blogs, workshops, or internal documentation that make these concepts accessible and engaging.
Another example could be finding yourself at ease automating repetitive tasks that bog down your team. Your niche is identifying efficiency drains within your team’s workflow by creating custom scripts or leveraging existing tools to automate these tasks. This way, you’ll be freeing up time for your team to focus on more impactful projects.
By adopting the doctrine of relentless utility, you’re not just filling a role; you’re carving out an area of focus where you can truly excel and provide unmatched value.
Remember, the niche you carve out today may not remain your niche tomorrow. Continuously explore, learn, and iterate, allowing your niche to evolve alongside your skills, interests, and the changing needs of your team. This ongoing journey of adaptation ensures your contributions remain impactful and aligned with both personal growth and team objectives.
Closing thoughts
We find ourselves at a juncture similar to the one brought about by the printing press and the typewriter. The fears are familiar – concerns about job displacement, the devaluation of human expertise, and the uncertainties of a shifting professional landscape.
Yet, if history has taught us anything, it’s that with disruption comes opportunity. Just as the printing press opened up the world of knowledge and the typewriter transformed the professional landscape, AI will redefine software engineering. It will challenge us to elevate our roles beyond coding, to think like entrepreneurs, and to build a more multi-faced identity.
The future of software engineering isn’t about clinging to the past but one where AI helps us build unimaginable things.
This article was originally published on LeadDev.com on April 4th, 2024.

{kind=link}
{kind=link}
{kind=link}