While returning home from my company offsite, I was standing in the TSA line, placing my belongings into the gray bins. It was then that a question caught me off guard.
“Have you ever been on a flight?”
I froze, my hands mid-air, gripping my shoes. The question, coming from a man in his thirties behind me, felt like a jab, wrapped in a thin veil of innocence. Why would he ask that? Was it my slightly fumbled handling of the trays, or had I committed some cardinal sin of air travel in his eyes?
“Yes, I have,” I responded, the words laced with a defensive edge. His question had pricked at something, a mix of annoyance and curiosity. Was it so apparent that I was out of my element, or was he just being snarky?
“It’s my first flight,” he then confessed, his tone shifting, revealing a mix of excitement and nervousness. “I wasn’t sure if my bag needs to go in the tray.”
In that moment, my assumptions hung heavily between us. The question wasn’t a snarky jab but a genuine plea for guidance, cloaked in the vulnerability of a first-time flyer. I had been so quick to assume malice, to paint his curiosity as a critique, that I nearly missed the human element, the shared experience of navigating unfamiliar territories.
“Yes, they are expecting the bags to be on the tray,” I found myself saying, the words coming out more as a realization of my own hasty judgment. I added, “Hope you have a great first flight!”
This encounter, brief and seemingly inconsequential, served as a profound lesson. It reminded me that our assumptions, especially those tinged with defensiveness, can cloud our judgment, that behind every question lies a story, a context we might not immediately understand.
As I watched him walk towards his gate, I was reminded just earlier in the offsite how my team and I were discussing how we admired Reddit’s “Default Open” value. This moment underscored the importance of giving others the benefit of the doubt, of approaching interactions with default openness. For in the end, we are all navigating our own journeys, sometimes confidently, sometimes with hesitation, but always moving forward, one question at a time.
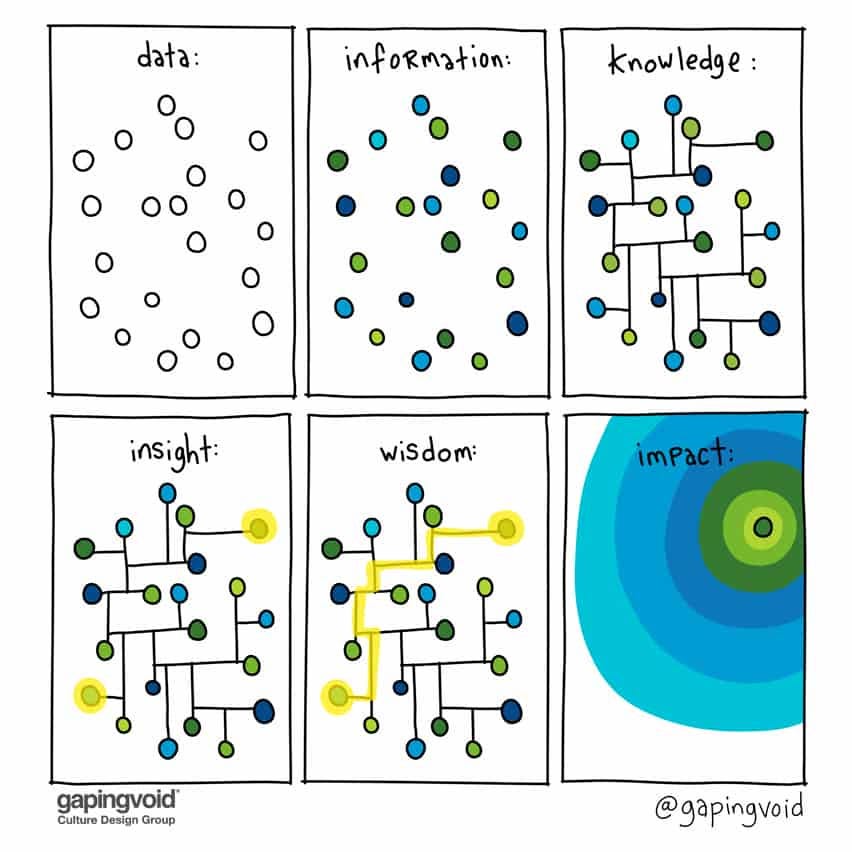
Remember scrambling for notes, losing ideas to the ether, struggling to keep up with tasks, and drowning in a sea of information? Yeah, me too. But that was before I understood Personal Knowledge Management (PKM).
In my previous post, we explored the essentials of PKM and Tiago Forte’s The 4 Levels of Personal Knowledge Management. Since then, I have received numerous requests for practical tips on how to master PKM, and many people have been curious about my own approach to it.
So today, we dive deeper, and I will share some tips on how you can achieve your own Personal Knowledge Mastery. Let’s break it down, level by level, and see how we can start getting insights out of information to drive impact.
If you want to build a great PKM practice, you need to have a way to capture information with the least amount of friction, both on the go and on the computer. Fumbling with clunky or slow apps will get you to focus on the app vs. what you were there to begin it and will cause you to lose motivation.
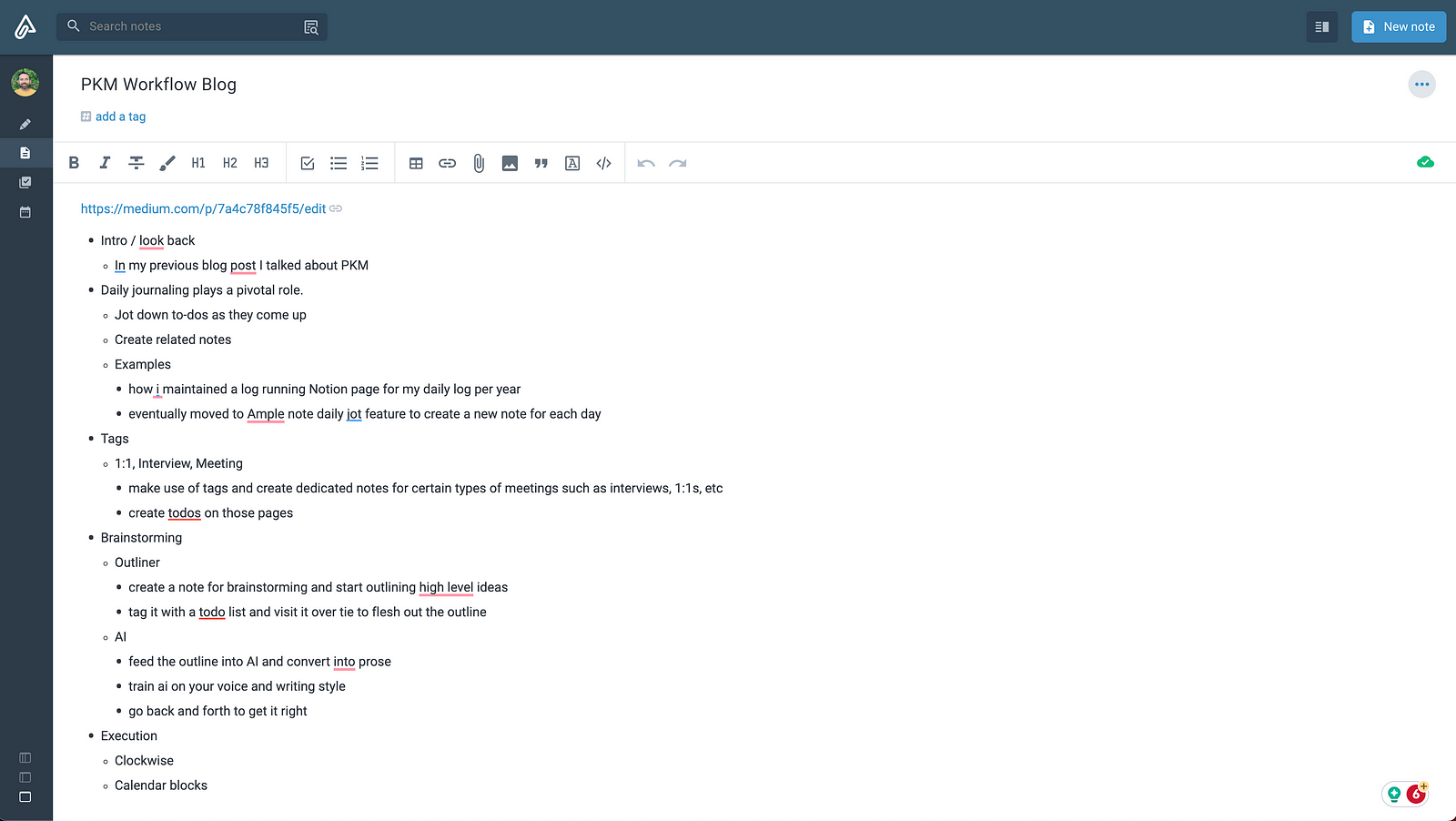
After experimenting with various tools like Logseq, Roam, and RemNote, I found my match in Amplenote. Its ability to sync notes cross-platform and the simple UX met my need for portability and simplicity.
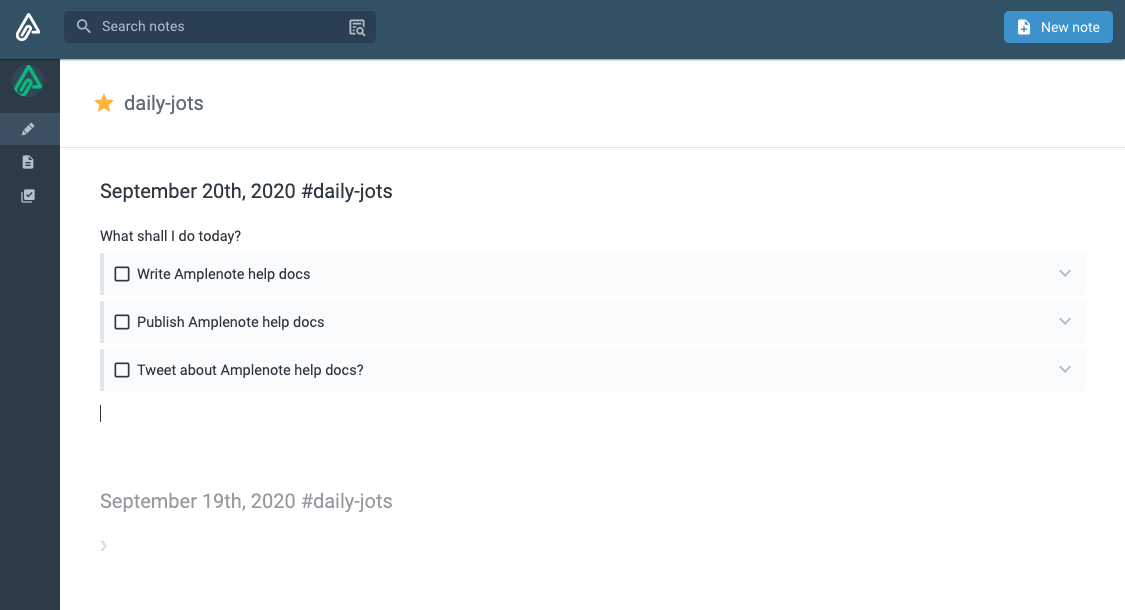
Each day, Amplenote’s “daily jot” feature automatically creates a new note, which I love. I used to do this manually in Notion by creating a running list of notes per day for each year before I switched over.
I usually capture the top things I want to focus on or accomplish that day. This is also similar to the technique recommended in the book Make Time if you want to learn more. I also use the daily journal to capture interesting links, code snippets, or ideas I come across that I can revisit later. This allows me to keep the number of tabs I have open to only a handful, reducing my mental clutter.
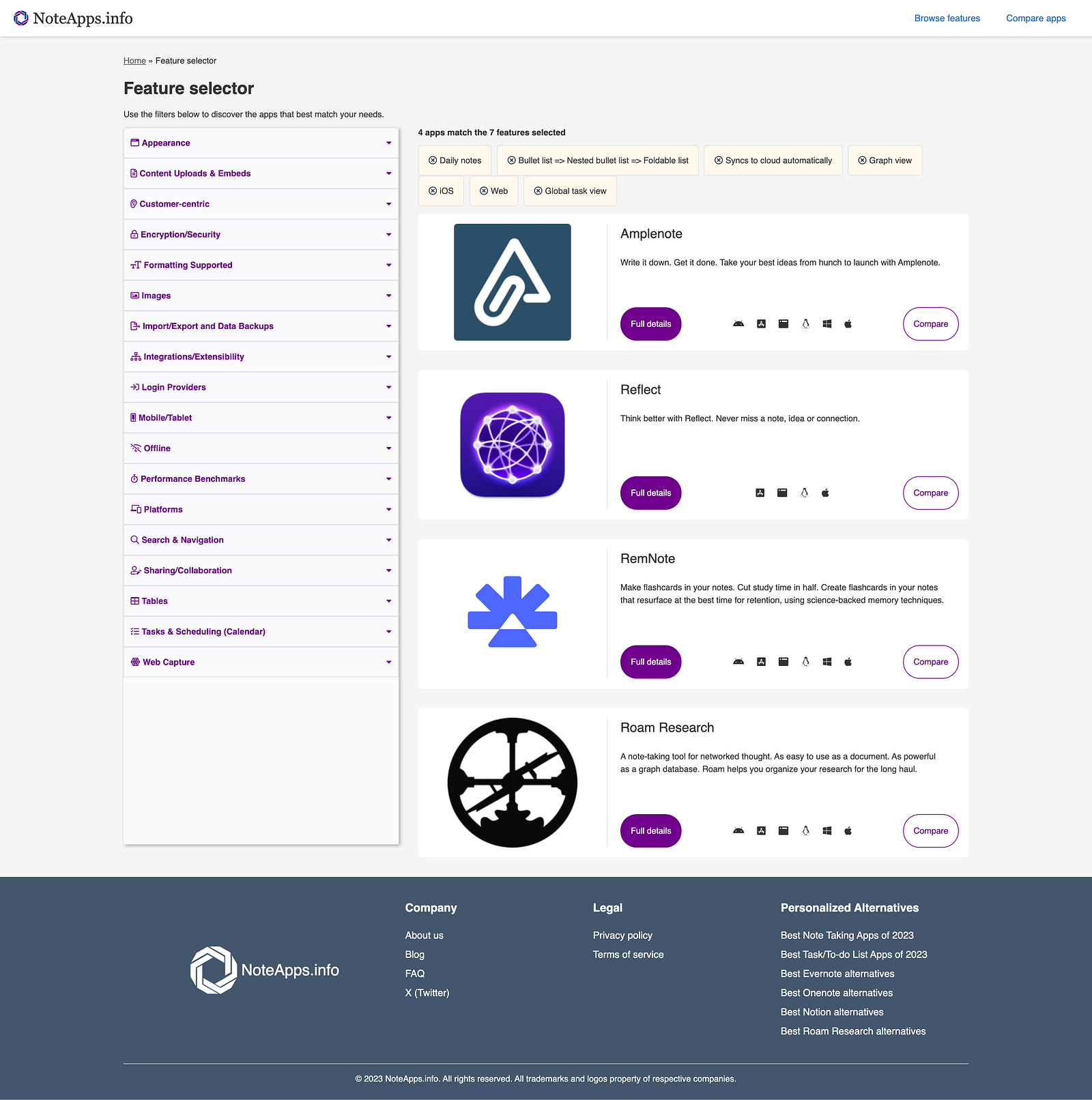
If you are looking for an app that has all the features I mentioned in this post, such as daily journaling, task management, note-taking, graph view, outlining, and cross-platform compatibility, then you should check out NotesApp.Info to find the one you like. Currently, only a few apps meet all these specific requirements, but you can change the filters based on your preferences to see more options.
Having a quick system for jotting down thoughts is just the beginning; managing long-form notes efficiently is equally important.
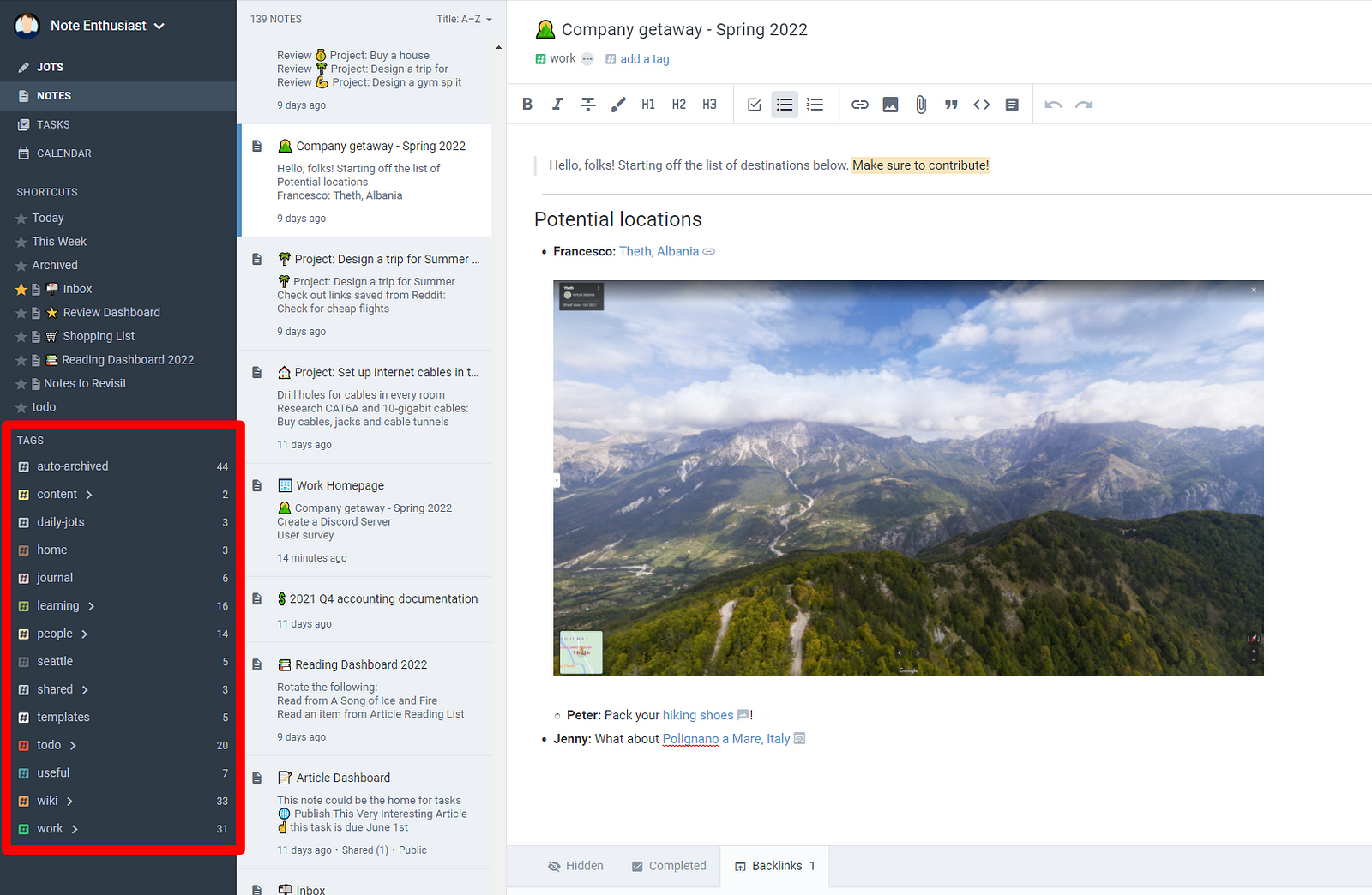
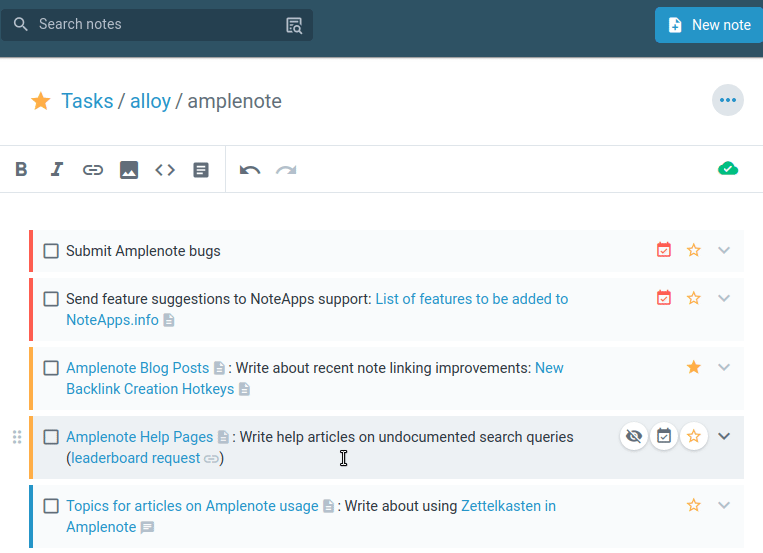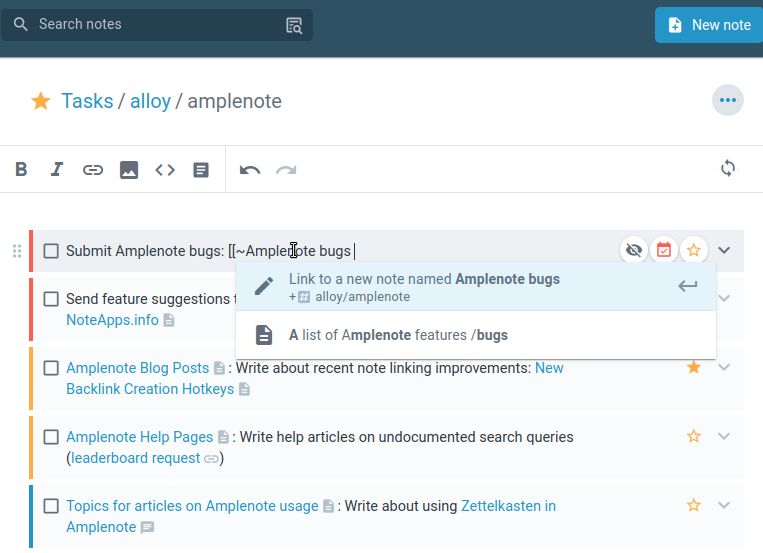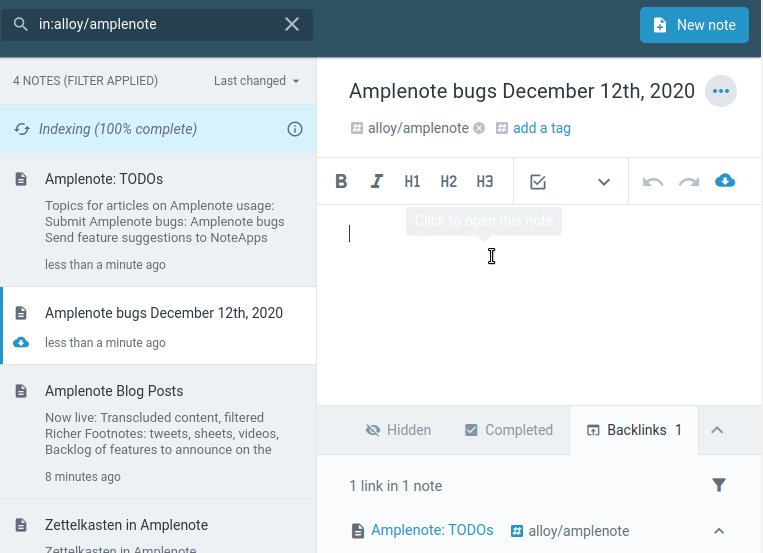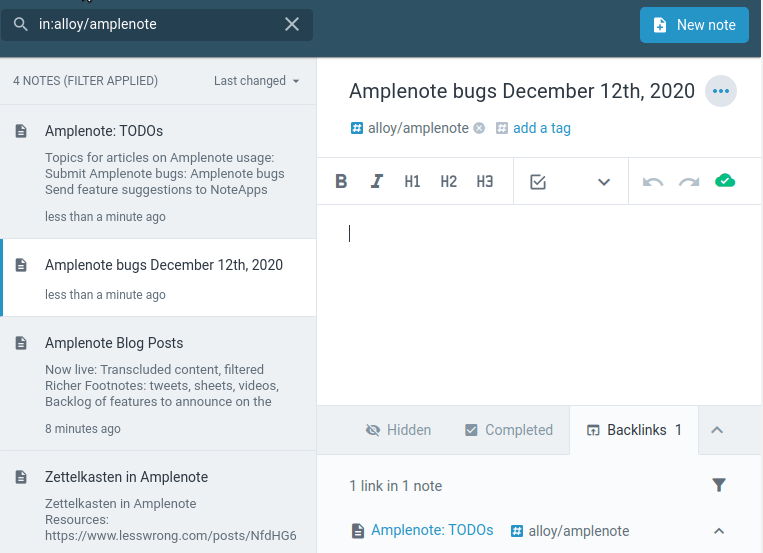
I use Amplenote to tag and organize various notes — #brainstorm for creative ideas, #meeting for general discussions, #interview for candidate assessments, #1–1 for personal meetings, and so on. This streamlines the retrieval and connection of related information.
Now, I can go back and review every meeting interaction and keep track of action items without dropping the ball, which brings us to the next point.
Ideas from my notes often evolve into tasks. I use dedicated notes for brainstorming, later converting these thoughts into actionable tasks within Amplenote.
So, for example, I had a task to “Write a blog post about [[Achieving PKM Mastery]]”. And I tagged my note as part of that task. I would then visit that note when I got a chance to flesh out the blog post’s content. So, I’m not pressed to produce something in one go but rather to make incremental progress. I usually have several tasks, such as writing proposals, blog posts, social media posts, etc., where I make incremental progress as inspiration strikes.
This technique has been a major unlock in boosting my productivity. I can now think about multiple projects simultaneously without feeling the pressure of producing a finished product. This approach is similar to the concept of evergreen notes, where the notes are not just temporary scribbles but are improved and updated over time as the author gains more knowledge and clarity on the subject matter.
My notes usually start out as an outline and then are fleshed out gradually. That’s one reason I really love outliner tools such as Roam Research, Logseq, etc, where everything starts out as a bullet by default.
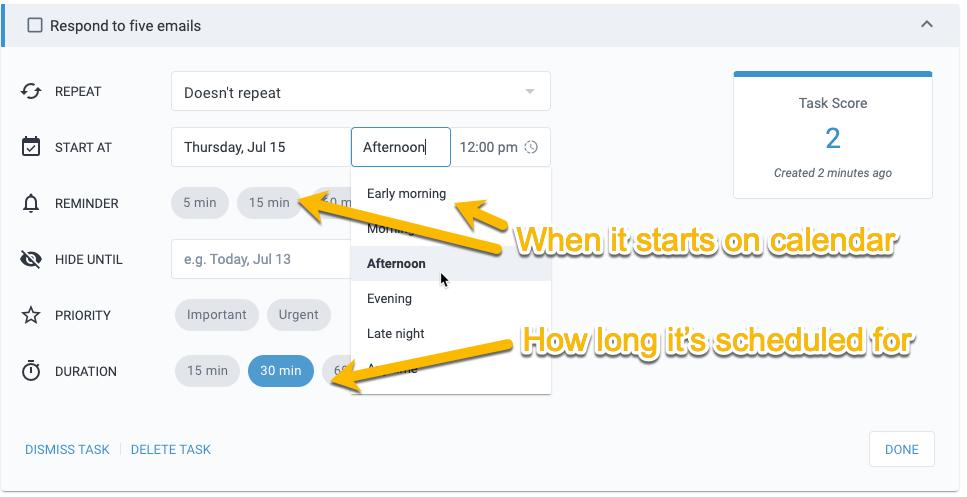
Tasks can also be assigned a date, effort, and importance, which gives them a “Task Score”, which is essentially a prioritized raking. I generally do this for more time-sensitive or important tasks so they are bubbled up at the top.
The key is not to prioritize what’s on your schedule, but to schedule your priorities. — Stephen Covey, The 7 Habits of Highly Effective People
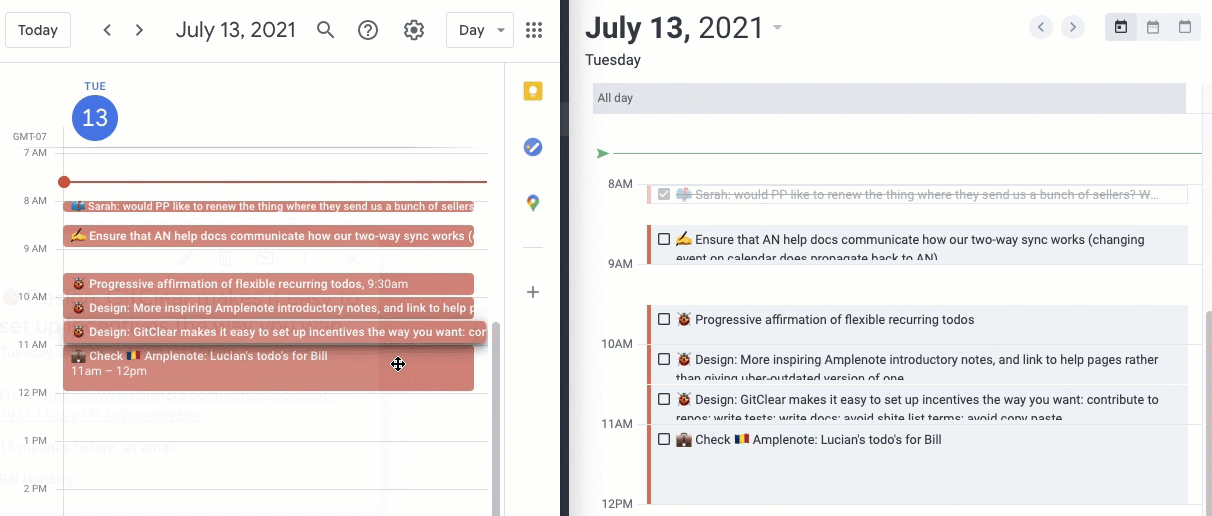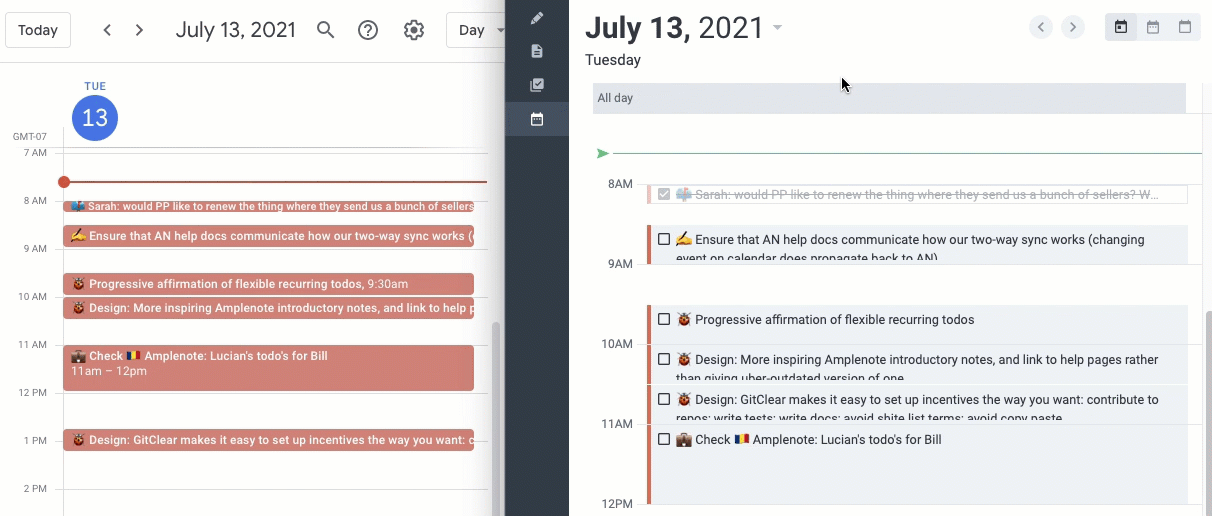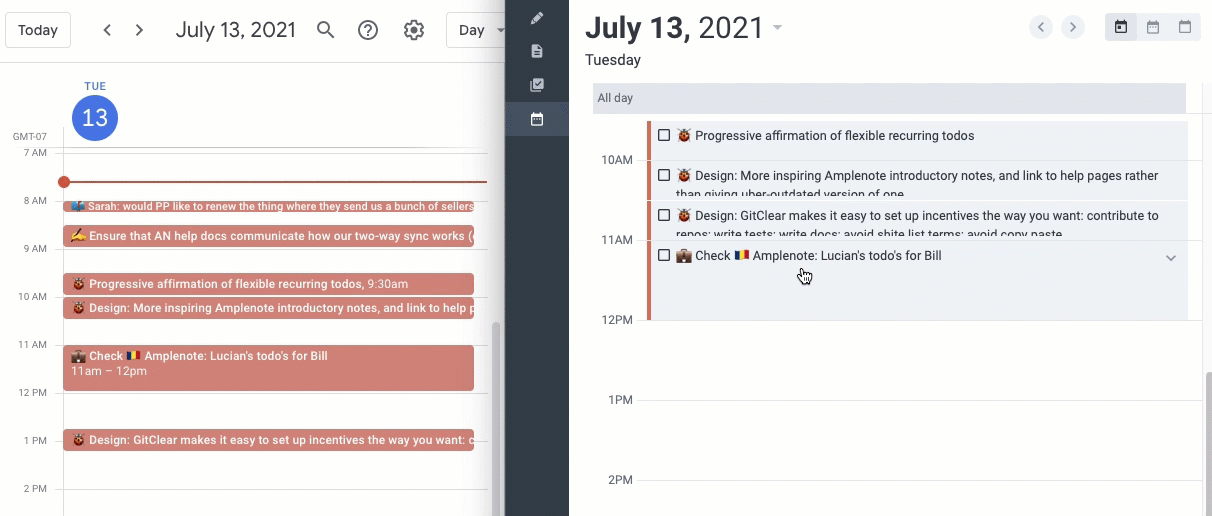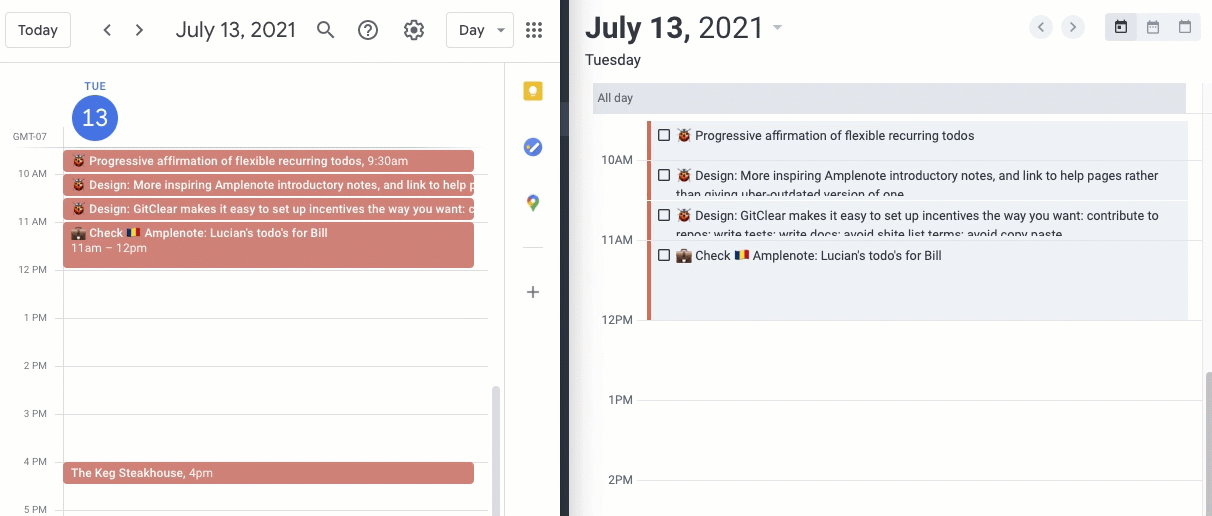
I’m a big believer in scheduling time to accomplish tasks on the calendar. For me, I’ve found that if it’s not on the calendar, it’s not going to get done because other meetings, distractions, and priorities take over. I usually schedule work blocks on my calendar per task manually, but Amplenote also offers a bi-directional calendar sync where this can be done automatically if you like.
For optimal calendar scheduling and making time for executing tasks, I highly recommend using Clockwise or Reclaim AI. Especially if you are in a meeting-heavy role, they are akin to having a personal assistant manage your calendar.
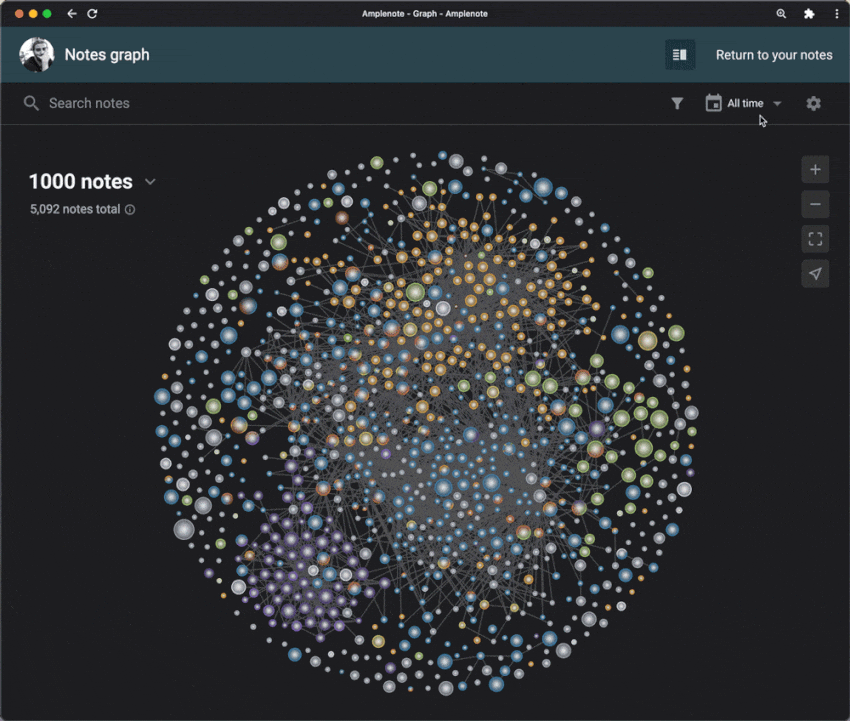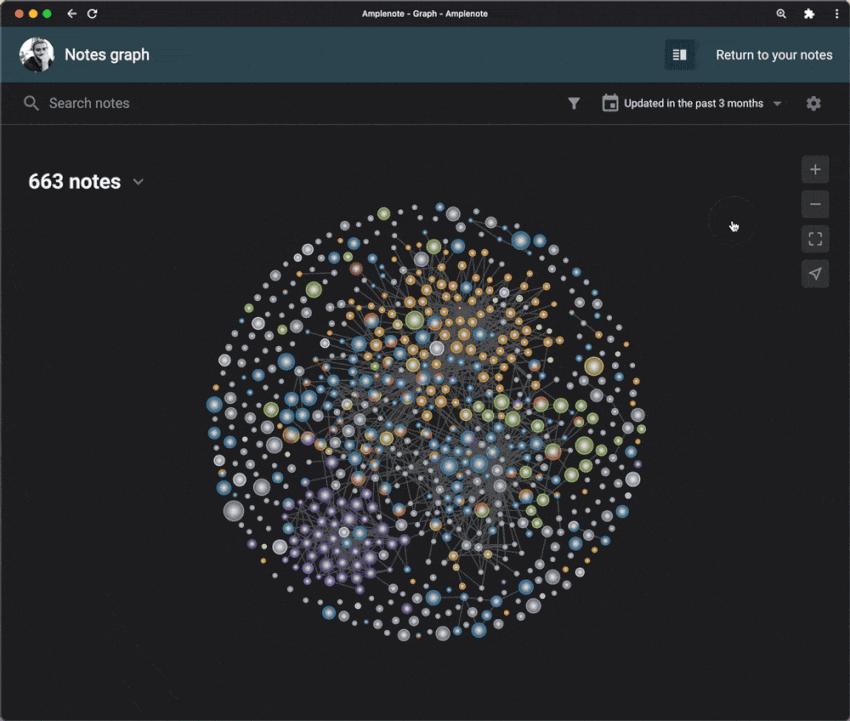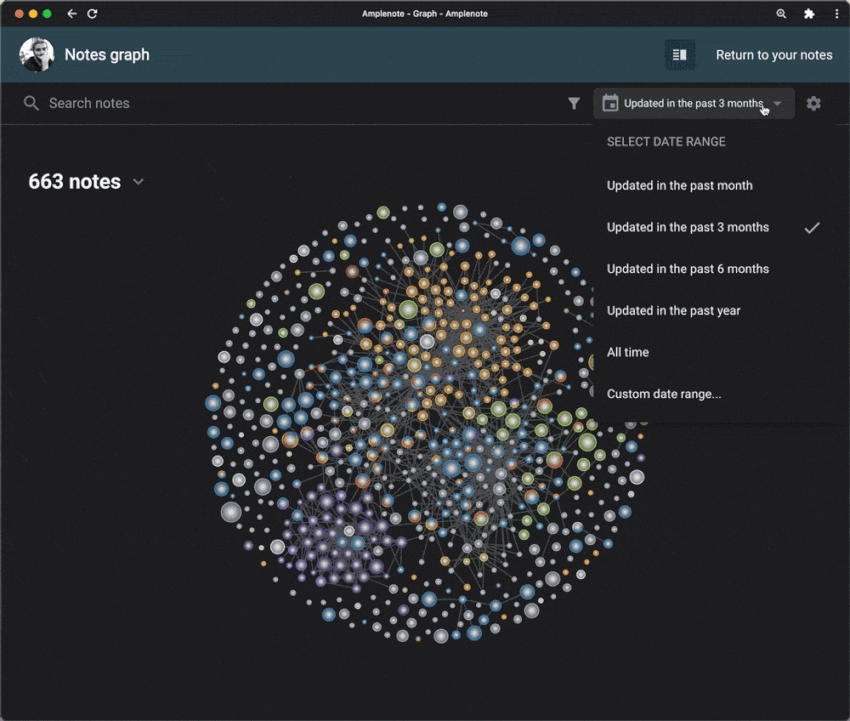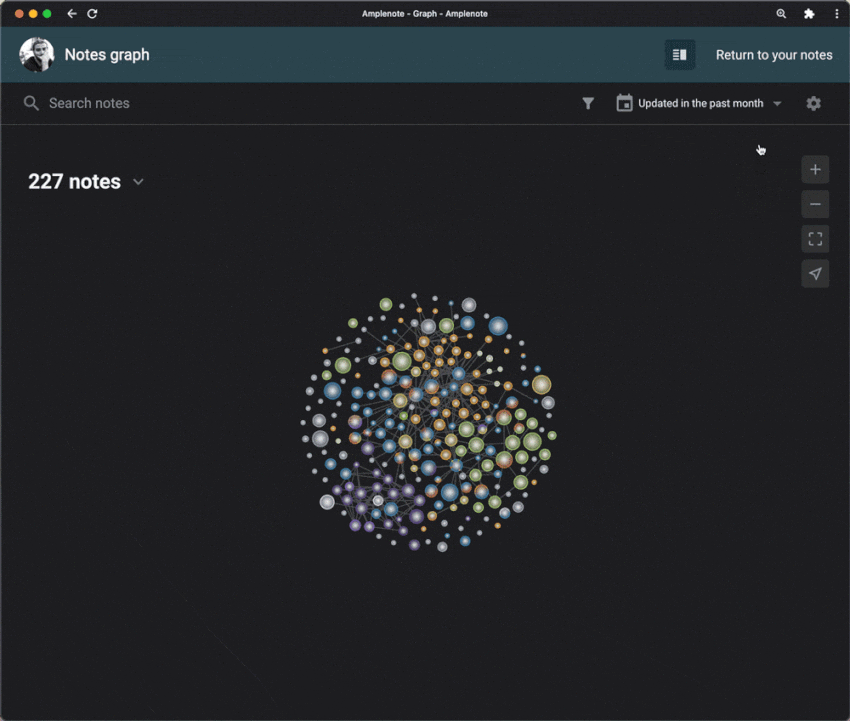
Finally, after building a system to store, manage, and act on information, you can extract insights from it. You can visualize how your ideas connect with each other in a graph and start seeing connections you may not have noticed before. This is a great way to gain a deeper understanding of the information you have gathered and make better decisions based on it.
Having a personal information store also means you can leverage AI to extract insights from your notes using frameworks such as LangChain or LlamaIndex. Here’s a demo I built using my Notion notes and LlmaIndex, where I could ask questions to AI based on my own corpus of information:
🤓 I've had a habit of manically maintaining a daily work journal in Notion since 2016
Now it's possible to extract insights from this personal data gold mine 🪄
🧵Here's how I built a personal Notion GPT in 15mins with:
While that requires writing a bit of code, off-the-shelf tools like Tavrn and others allow you to connect a corpus of information and ask questions based on it.
Conclusion
“We are drowning in information, while starving for wisdom. The world henceforth will be run by synthesizers, people able to put together the right information at the right time, think critically about it, and make important choices wisely.” — E. O. Wilson
In our journey towards mastering Personal Knowledge Management, we’ve explored methods not only to gather and categorize information but also to synthesize and extract meaningful insights from it.
As the renowned American biologist E. O. Wilson aptly put it, our challenge is to navigate the ocean of information to find wisdom. This journey through the levels of PKM equips us with the tools to be effective synthesizers — those who can effectively collect, connect, and utilize knowledge to make good decisions.
I’ve been fortunate enough to lead teams in various environments, from small start-ups to large organizations, and along the way, I’ve received consistently positive feedback on my teams’ camaraderie, cohesion, and performance. That and hearing many times from my direct reports that I’ve been one of the best managers they’d had made me wonder what exactly was working well.
I don’t think I was super deliberate about it, to be honest. I just did what felt right intuitively over time. Maybe my experience being on the engineer manager pendulum allowed me to keep my ear to the ground and do what I would have wanted to see from my manager as an IC.
In any case, this is my attempt at writing down some of my implicit strategies into an explicit guidebook for myself and others to reference and follow. This is not meant to be a comprehensive resource such as MGMT Accelerator or The 15 Commitments of Conscious Leadership, which I highly recommend, but just things I found putting the most amount of emphasis on. I’ll also note that you don’t need to be a manager to find this relevant. Effective leadership is a key skill for everyone to master.
So, after doing some reflection, I was able to boil down this essence of effective leadership to six critical elements, which I like to call the ‘6 Cs’. In this post, I’ll share these key elements, each backed by practical strategies and real-life lessons that can redefine how you lead. So, without further adieu, let’s dive in.
1. Communication
Transparent and authentic communication is the cornerstone of effective leadership. It’s not merely about conveying information but about involving team members in decision-making processes, even when ideas are still in their formative stages. This practice fosters a sense of ownership and collaboration.
This also extends to offering constructive feedback, where I aim for open and candid conversations without the proverbial “shit sandwich.” This authentic management style fosters workplace transparency, clarity, and directness. It empowers employees to clearly identify areas where they can make the most meaningful contributions to the team’s success.
Some professionals say you need to have a praise-to-criticism ratio of 3:1, 5:1, or even 7:1. Others advocate the “feedback sandwich” — opening and closing with praise, sticking some criticism in between. I think venture capitalist Ben Horowitz got it right when he called this approach the “shit sandwich.” Horowitz suggests that such a technique might work with less-experienced people, but I’ve found the average child sees through it just as clearly as an executive does. — Kim Malone Scott, Radical Candor
Key practices:
Hold regular one-on-one meetings with a running agenda to discuss your team’s ideas and concerns.
Establish a culture of active listening where team members feel heard and valued.
Leverage collaborative tools that allow team members to contribute to decisions and ask questions async.
Establish a career plan document where you keep track of goals, ideas, and growth conversations and review it at least on a monthly basis.
Questions to measure success:
Do you regularly cascade relevant strategy and business updates to your team members from the company leadership?
Do your team members feel like they are part of shaping the ideas from the early stages and are involved in the decision-making process?
Do your team members regularly receive ongoing feedback rather than just surprising feedback during formal touchpoints like performance review cycles?
2. Connection
Connection is built on the foundation of authentic and transparent communication. Team cohesion and trust are something I value deeply, and I aim to create an environment that values inclusivity, empowerment, and psychological safety.
A team is not a group of people who work together. A team is a group of people who trust each other.— Simon Sinek, Leaders Eat Last
I’ve used many rituals and practices, such as retrospectives, all hands, happy hours, pulse surveys, etc., with the aim of building connection and trust. No matter the ritual, it comes down to ensuring that every team member’s voice is heard and respected.
Creating opportunities for the team to bond outside of work is also particularly effective. This includes team happy hours, get-to-know sessions where team members share their passions and interests, and even occasional team retreats to strengthen in-person connections.
Key practices:
Schedule regular team retrospectives to examine what’s going well and what can be improved. Commit to action items based on the feedback and continue to iterate.
Foster mentorship and peer support within your team.
Encourage cross-functional collaboration to build relationships with other teams.
Share stories of successful team collaborations and their impact on projects.
Questions to measure success:
Do your team members believe they have agency in shaping how the team operates?
Is there a mechanism in place to continually examine team processes and iterate based on feedback?
Does the team regularly interact with each other in informal settings such as happy hours or retreats?
3. Composure
Amidst challenges and crises, maintaining composure is essential. Using the team as an outlet for venting emotions is tempting, but this can be counterproductive. Instead, I’ve learned to adopt a methodical approach: analyzing the situation, acknowledging emotions, outlining a clear plan, and providing transparent updates.
In my experience, team members look to their leaders as beacons of stability during turbulent times. They appreciate leaders who don’t just react emotionally but engage in constructive problem-solving. In fact, research suggests that for almost 70% of people, their manager has more impact on their mental health than their therapist or their doctor.
When interpersonal disagreements or conflicts arise, lean into curiosity to understand why. This is often not an easy thing to do. In her book “Dare to Lead,” Brown uses the term “rumble” to describe a discussion or conversation that is defined by a commitment to lean into vulnerability, stay curious and generous, and be fearless in owning our parts.
A rumble is a discussion, conversation, or meeting defined by a commitment to lean into vulnerability, to stay curious and generous, to stick with the messy middle of problem identification and solving, to take a break and circle back when necessary, to be fearless in owning our parts, and, as psychologist Harriet Lerner teaches, to listen with the same passion with which we want to be heard. More than anything else, when someone says, “Let’s rumble,” it cues me to show up with an open heart and mind so we can serve the work and each other, not our egos.―Brené Brown, Dare to Lead: Brave Work. Tough Conversations. Whole Hearts
She believes that during moments when we’re pulled between our fear and our call to courage, we need shared language, skills, tools, and daily practices that can support us through the rumble.
Key practices:
Establish a culture of practicing non-violent communication or The Story Rumble to help the team effectively and compassionately navigate difficult conversations and conflicts.
Create space to practice mindfulness exercises as a team to help manage stress during challenging times.
Run premortems ahead of major milestones and launches to avoid last-minute surprises and stressful fire drills.
Establish an on-call rotation with predefined roles and responsibilities and detailed runbooks to handle emergencies.
Encourage the team to take time off after intense periods and plan for their absence to allow them to recharge without pressure or guilt.
Questions to measure success:
Does your team feel that they have reliable support during challenging times?
Do you maintain composure and engage in constructive problem-solving rather than venting emotions during crises?
4. Curiosity
Fostering a culture of continuous learning has been a personal passion of mine. I’ve encouraged my team to embark on a journey of exploration, whether through experimentation, reading, or mentorship, to build their personal mastery. This means holding brown bag sessions and providing opportunities for team members to work on experimental ideas, fostering a culture of perpetual learning.
I’ve also seen the importance of extending this curiosity to understand our customers and the business deeply. To truly solve their problems, the team needs to immerse themselves in the customer’s perspective and become students of the business.
The highest quality of thinking cannot emerge without learning. Learning can’t happen without mistakes.― Liz Wiseman, Multipliers: How the Best Leaders Make Everyone Smarter
Key practices:
Organize regular “knowledge-sharing” or “brown bag” sessions where team members present on topics of interest or discuss industry-related books or articles.
Set aside time for team members to explore new technologies, ideas, or tools relevant to their work.
Create opportunities for the team to interact directly or indirectly with customers by fielding support cases or listening in on sales calls.
Questions to measure success:
Do you create space for the team to experiment and fail in their learning journey without it being held against them?
Does the team interact with its customers on a regular basis?
5. Clarity
Clarity serves as the guiding light in decision-making. It’s not just about relying on data; it’s about relying on the right data.
I have found setting ambitious yet achievable goals, defining clear KPIs, and diligently tracking progress have created an immense amount of clarity for the team. In addition, we created a long-term roadmap, acknowledging its inherent uncertainty, and broke it down into detailed plans every quarter to create a seamless runway for execution.
This clarity extends to written communication, where everything from team working norms to schedules and expectations is documented. Having an operating playbook in place ensures that new team members can seamlessly integrate into the team and hit the ground running.
Ideas are easy. Execution is everything. — John Doerr, Measure What Matters
Key practices:
Leverage thinking tools and frameworks to help you and your team solve problems, make decisions, and understand systems.
Create a team charter that outlines norms, expectations, and communication guidelines.
Use project management tools to track progress transparently and provide visibility into goals.
Create an organized repository for regularly updated documentation, making it easy to access important information.
Ensure new team members have a clear checklist of things they can accomplish or learn in the first 30, 60, and 90 days.
Questions to measure success:
Does your team possess a clear operating playbook, ensuring seamless onboarding for newcomers?
Are goals and KPIs well-defined, and is progress diligently tracked?
6. Celebration
Recognizing and celebrating achievements, no matter their scale, injects joy into the workplace. Acknowledging accomplishments through company-wide accolades or simple ‘kudos’ fosters a sense of pride and motivation.
Leadership is not about being in charge. It is about taking care of those in your charge. — Simon Sinek, Leaders Eat Last
Key practices:
Establish a practice to regularly recognize people behind their exceptional contributions and celebrate their impact.
Host regular team celebrations for project milestones, both big and small, and send out swag and small tokens of appreciation.
Establish a public forum for team members to express gratitude and recognition for their colleagues.
Establish a public forum for sharing success stories highlighting their positive impact.
Questions to measure success:
Is team spirit consistently high, and do team members eagerly anticipate celebrating successes together?
Are creative ways employed to foster team bonding, even in distributed work settings?
Closing Thoughts
I hope you found valuable takeaways from these 6 Cs. These principles aren’t just personal opinions; they’re insights drawn from practical experiences and even backed by research at BetterUp, which happens to be my former employer and a place where I’d like to think I earned my stripes for leadership:
We found that managers who can strengthen their coaching and problem solving skills, be more authentic with their teams, and work to recognize employee contributions are riding a wave of effectiveness to the bank: Their organizations experience a +400% return on assets, +30% EPS 5-year growth, +17% boost in innovation, and more. — Mindsets on the move: what effective management looks like today, BetterUp Briefing
You could use these 6 Cs as a way to conduct a health check for your team and see where you need to focus your energies. I would love to hear your thoughts and experiences as you apply the 6 Cs to your leadership journey — please feel free to share your feedback and stories!
Effective proposal writing techniques for engineering leaders
As an engineering leader, you’ve likely faced the challenge of writing proposals for ideas you’re passionate about, whether it’s drafting design docs, request for comments (RFCs), memos, or even slide decks. The format might change depending on context, but the fundamental challenge remains: how do we make our ideas resonate?
Throughout my career, I’ve witnessed numerous promising ideas fall by the wayside or need a lot of back and forth due to a lack of clear articulation. The culprit? Often, a missing ingredient from the six crucial elements of a persuasive proposal.
Knowing how to craft proposals that communicate and inspire action will ensure that your next proposal isn’t just read, but acted upon.
1. Establish context
At the heart of a compelling proposal lies the establishment of mutual understanding. Begin by elucidating the “why.” Resist the urge to dive straight into the solution.
For instance, if you’re proposing a shift in system architecture, listing the current system’s flaws might seem intuitive. However, the real starting point should be “Why now?” What future changes do you foresee that necessitate this shift? Relate your proposal to your organization’s KPIs, OKRs, or overarching strategy.
Drawing inspiration from Stephen Covey’s The 7 Habits of Highly Effective People, it’s paramount to prioritize understanding before seeking to be understood. By ensuring your proposal resonates with your audience’s concerns, you pave the way for consensus.
Example of establishing context in a proposal:
With the rapid growth of our user base and the increasing complexity of our application, our existing architecture is becoming a bottleneck. Recent post-mortem analyses of outages have pointed to scalability and tight coupling issues.
Our company’s OKRs aim for a 20% increase in user engagement and a 30% growth in active users over the next year. To achieve this, we need an architecture that is resilient, scalable, and can be iterated upon quickly.
2. Identify the problem
Once mutual understanding is established, it’s imperative to identify the core issue or opportunity your proposal targets.
Begin by articulating the current state, grounding your discussion with metrics and data. Subsequently, spotlight the primary areas of concern with the existing situation and, based on this, formulate your hypothesis.
Overall, you should seek to emphasize the gravity and ramifications of the problem, positioning yourself as the authority spotlighting an urgent issue.
Example of identifying the problem in a proposal:
Current state:
Our monolithic application has been the backbone of our services for the past five years. During this time, we’ve seen:
User growth: A 300% increase in active users.
Feature expansion: The introduction of 50+ new features, increasing the complexity of our codebase.
Deployment frequency: An average of one thousand deployments per month, with each deployment introducing an average of three new features or improvements.
While this growth and activity indicate a thriving product, they’ve also introduced challenges:
1.Latency concerns: Our API response times have gradually increased over the past year. During high-traffic periods, we’ve observed a 30% increase in API response times compared to the previous year, impacting user experience.
2.Tight coupling: The intertwined nature of our services has become more evident. 20% of new feature releases in the past six months have resulted in regressions in unrelated areas, indicating a lack of modularity and separation of concerns.
3.Deploy time: The complexity of our application has affected our deployment times. Each deployment now takes an average of one hour, a 25% increase from the previous year. This affects our ability to swiftly deliver value to our users andmaintain a reasonable MTTR.
Hypothesis:By migrating to a microservices architecture, we can achieve faster deployment cycles, better scalability, and independent service evolutions, leading to improved uptime and stable user experience.
3. Present options
When proposing solutions, it’s vital to consider various options. As Chip Heath and Dan Heath advise in Decisive: How to Make Better Choices in Life and Work, follow the W.R.A.P process: widen your options, reality-test your assumptions, attain distance before deciding, and prepare to be wrong.
This also builds credibility as an honest analysis rather than a biased proposal. This stage is about demonstrating your critical thinking skills.
Example of presenting options in a proposal:
Option 1: Incremental refactoring Pros: Lower immediate risk, can be done during regular sprints. Cons: Longer overall transition period, potential for accumulating tech debt.
Option 2: Big bang rewrite Pros: Clean slate, can design with best practices from the start. Cons: High risk, requires significant resources, longer time to see benefits.
Option 3: Hybrid approach (starting with core services and expand outwards) Pros: Balances risk and allows for learning and iteration. Cons: Requires careful planning and coordination.
4. Create a roadmap
With a recommended solution, it’s time to detail the implementation. Envision your proposal as a meticulously planned sequence.
Create a timeline detailing the steps, assign responsibilities, and set expectations for each stage.
Like a conductor leading an orchestra, your proposal should coordinate a unified effort toward the intended result.
Phase 2: Develop the first set of microservices and integrate them with the existing system. Duration: 3 months Responsible: Teams A and B
Phase 3: Gradual rollout to a subset of users and gather feedback. Duration: 1 month Responsible: QA team, DevOps, and user feedback group
Phase 4: Full transition and decommissioning of old components. Duration: 2 months Responsible: All engineering teams
5. Highlight risks
Analyze potential risks and challenges associated with the proposal, as well as the likelihood and impact of those risks. Provide strategies or plans to mitigate these risks, showing preparedness and foresight.
Examples of highlighting risk in a proposal:
Risk: Integration challenges with existing systems Likelihood: High Impact: Moderate Mitigation: Begin with a pilot project focusing on one or two core services to understand integration pain points. Use this pilot to develop best practices for subsequent integrations.
Risk: Potential downtime during transition Likelihood: Medium Impact: High Mitigation: Schedule migrations during off-peak hours and ensure rollback strategies are in place. Communicate potential downtimes to stakeholders well in advance.
Risk: Team’s learning curve with new architecture Likelihood: High Impact: Medium Mitigation: Invest in training sessions and workshops focused on microservices best practices. Pair experienced team members with those less familiar during the initial phases.
Risk: Increased initial costs Likelihood: Medium Impact: Medium Mitigation: While there might be an upfront cost due to the transition, the long-term benefits in terms of scalability, maintainability, and faster deployment cycles are expected to offset these initial expenses. Regular cost-benefit analyses will be conducted to ensure we remain on track.
Risk: Complexity in monitoring and logging across services Likelihood: Low Impact: High Mitigation: Adopt centralized logging and monitoring solutions that provide a holistic view of the entire system. This will aid in quicker issue detection and resolution.
6. Prompt action
Summarize the proposal’s main points and clearly state what you’re asking stakeholders to do next, whether it’s providing feedback, giving approval, or allocating resources.
Include any additional information, data, charts, or references that support the proposal but might be too detailed for the main body. This provides a deeper dive for those interested.
Example concluding aspect of a proposal:
In light of the challenges posed by our current monolithic architecture and the company’s ambitious growth targets, transitioning to a microservices approach emerges as a strategic imperative. The hybrid approach, which combines the strengths of incremental refactoring and a more comprehensive rewrite, offers a balanced and pragmatic path forward.
We’ve identified potential risks associated with this transition and have proposed robust mitigation strategies to address them. The success of this initiative, however, hinges on a collaborative effort,cross-functional alignment, and shared commitment.
Next Steps:
Feedback round: We invite stakeholders to review this proposal and provide feedback by [specific date].
Pilot execution: Post feedback; if there are no strong objections or concerns, we will commence the pilot project.
We’re at a pivotal juncture, and the decisions we make now will shape our product and capabilities for years to come. Let’s collaborate, innovate, and steer our organization towards a future-ready architecture.
Final thoughts
In conclusion, crafting a persuasive proposal goes beyond organizing information in a digestible pyramid structure. It’s about weaving a narrative that resonates with the organization’s core objectives, prospecting a path forward, anticipating risks, and compelling stakeholders to take action.
When writing your next proposal, see it as more than a document. It’s a powerful call to action, a catalyst for change, and a testament to your leadership acumen. The quality of your proposals can shape the trajectory of your projects, teams, and, in the grander scheme, your evolution as an engineering leader.
This article was originally published onLeadDev.comon Nov 29th, 2023.
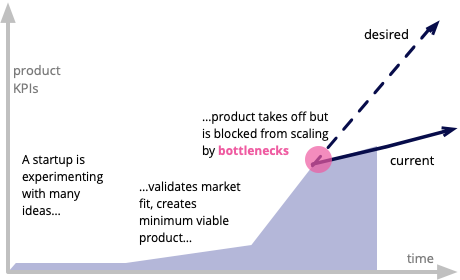
Most startups that go through hyper-growth tend to face the inevitable Bottlenecks of Scaleups, as masterfully described by ThoughtWorks.
Having navigated the hyper-growth journey myself, I’ve witnessed firsthand how these technical bottlenecks can impede business progress, causing churn and chaos.
In light of these challenges, I wondered if a system architect’s role could hold the key to identifying and circumventing these bottlenecks and reducing complexity like this infamous Amazon Deathstar.
To that end, this article explores the benefits, operating philosophy, guiding principles, job description, career progression, success criteria, and implementation approaches for the role of a system architect.
Benefits of having a System Architect
My hypothesis is rooted in the belief that a clear and purposeful approach to technical architecture can prevent false starts and accumulating tech debt.
Picture a system architect whose sole responsibility is to observe the big picture and facilitate knowledge sharing across teams, breaking down silos for better collaboration.
This individual would need to possess exceptional skills in designing and managing the overall technical architecture of a system. Their role includes assisting teams in defining system components, services, and interactions.
The benefits of having a system architect would ultimately translate into:
Improved alignment and coordination — Foster a common goal and architecture across teams, leading to more efficient and effective development.
Enhanced technical expertise — Offer a deep understanding of system design and architecture, guiding and mentoring other engineering team members to elevate the organization’s overall technical capabilities.
Improved quality and performance — Co-create a well-designed system architecture to boost performance and reliability, resulting in quicker time-to-value, better user experiences, and heightened customer satisfaction.
Reduced technical debt — Proactively manage system architecture to prevent tech debt buildup, saving time and resources in the long run.
Harmonizing With the Agile Philosophy
You may be curious how this role fits into the agile methodology that many organizations follow. On the surface, the role of an architect may be antithetical to being agile.
However, several sources discuss the role of an architect in an agile environment. For example, Agile Architecture describes it as:
The role of the architect in an agile project is to provide guidance and direction to the team on the technical aspects of the project. The architect is not a dictator, but rather a facilitator and coach, who helps the team find the best solutions to their technical challenges.
Similarly, the Scrum Alliance discusses the role, stating that:
[the architect] is responsible for guiding the team to make technical decisions that align with the project’s goals, scope, and delivery schedule. They should be able to communicate the technical vision to the team and help the team understand how their work contributes to that vision.
Large-Scale Scrum (LeSS) Framework’s view on the architecture role is more philosophically aligned with how I see the role. The following statements on the Architecture & Design page in the chapter “Technical Excellence” shape their opinion about software architects:
The sum of all the source code is the true design blueprint or software architecture.
The real software architecture evolves (better or worse) every day of the product, as people do programming.!
The real living architecture needs to be grown daily through programming by master programmers.
A software architect who is not in touch with the evolving source code of the product is out of touch with reality.
Every programmer is some kind of architect–whether wanted or not. Every act of programming is some kind of architectural act–good or bad, small or large, intended or not.
LeSS promotes the idea that architects are regular team members. They should participate in hands-on engineering and especially mentoring through design workshops and pair programming. LeSS warns against architecture astronauts (a.k.a. PowerPoint architects):
These are the people I call Architecture Astronauts. It’s very hard to get them to write code or design programs, because they won’t stop thinking about the architecture… They tend to work for really big companies that can afford to have lots of unproductive people with really advanced degrees that don’t contribute to the bottom line.
Now that we have some grounding philosophy behind a system architect’s role in an agile organization, let’s discuss the guiding principles of this role.
For this, we don’t need to reinvent the wheel. Principles proposed by Agile Architecture hold strong:
Value people — You must recognize the value and importance of people and their expertise. No dictators or PowerPoint architects.
Communicate! — Communicate effectively with all stakeholders and tailor information to their needs.
Less is more — Minimize complexity and strive for simplicity in design and communication.
Embrace change — Be prepared for change and welcome it as an opportunity for competitive advantage.
Choose the right solution for the enterprise — Customer centricity. Make sure the solution is right by verifying it with the customer.
Deliver quality — Foster a culture of craftspersonship and sustainable development at a pace that can be maintained indefinitely.
Model and document in an Agile fashion — Leverage proven and effective modeling/mapping and documentation strategies.
Carving the Job Description
Equipped with the guiding philosophy and principles, if you were to recruit someone for this role, let’s see what the job description could look like. A system architect typically collaborates with other teams in several ways:
Guide system design and architecture — Provide guidance and expertise to other teams on how to design and build systems that align with the overall architecture of the organization. This can involve working closely with teams to understand their needs and requirements and recommending the best approaches.
Review and provide feedback for technical designs — Review and provide timely feedback for RFCs proposed by teams. This can involve evaluating the proposed designs to ensure they align with the system’s overall architecture and do not introduce any potential issues or technical debt.
Help resolve technical challenges — Help teams resolve technical challenges during development. This may involve providing guidance on approaching a particular problem or working with the team to develop a solution.
Participate in planning and estimation — Participate in planning and estimation meetings with other teams. This can involve providing input on the technical feasibility of proposed features and estimates for the time and resources required to implement them.
Overall, the specific ways in which a system architect collaborates with other teams will vary depending on the needs and goals of the initiative and the members working on it.
Now that we have a job description, one may wonder how someone would become an architect and what would their career trajectory look like.
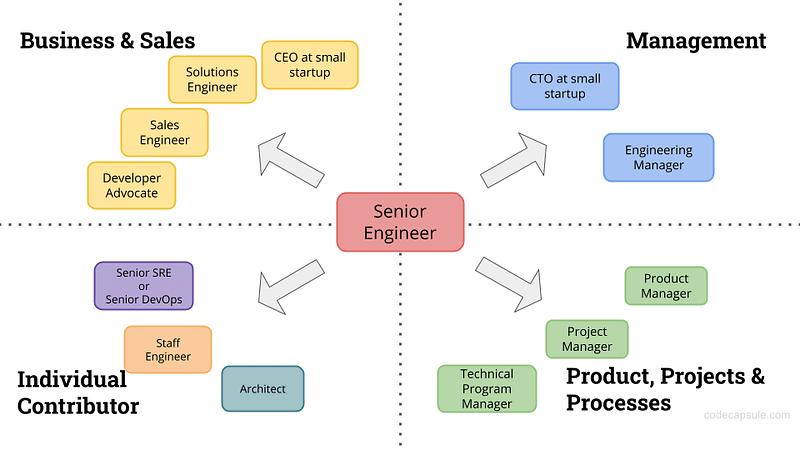
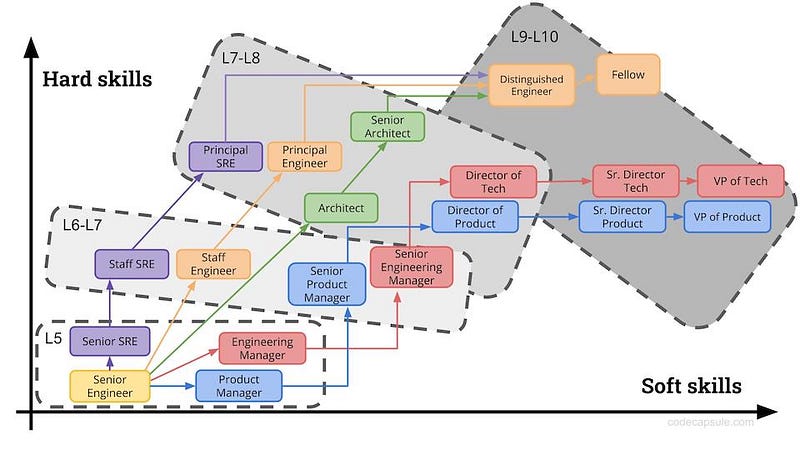
Various avenues exist for senior engineers to advance in their careers. On the individual contributor (IC) path, adding a system architect role alongside roles like SRE, Data Engineer, and Staff Engineer is a viable option.
Illustrations below help visualize what that may look like courtesy of CodeCapsule.
Note the key difference between an architect and staff/principal engineers: while the latter focus on ensuring their teams’ work functions correctly, architects take a broader view, looking after how all the pieces fit together.
Before you ask, yes, staff and principal engineers also do think about how their work fits into the broader ecosystem, but most often, they don’t consider that their full-time concern.
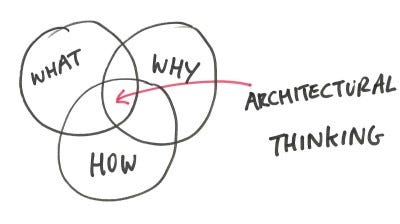
This role sits at the intersection of ‘What’ (is it we are trying to do/solve) and ‘How’ (are we going to approach the design), and ‘Why’ (are we doing it this way) as described by Peter Cripps.
Becoming an architect also has to do with having increased communication and relationship skills, on top of solid tech skills, as architects have to deal with and influence larger groups of people across multiple teams and organizations.
Measuring Success
Introducing the role of a system architect into an organization is a strategic move aimed at improving the technical architecture, fostering collaboration, and overcoming growth challenges.
However, to validate the effectiveness of this role, it’s essential to measure its impact and quantify the value it brings to the organization.
Here are some potential KPIs that can help gauge the effectiveness of the role:
Technical debt reduction: Measure the decrease in technical debt over time as a result of proactive architectural decisions made by the system architect. (Related: How Google Measures and Manages Tech Debt)
System performance and reliability: Evaluate the performance and reliability metrics of the system after the system architect makes architectural improvements.
Collaboration and team satisfaction: Conduct surveys or feedback sessions to gauge how well the system architect facilitates collaboration and team communication.
Time-to-Market reduction: Determine how architectural improvements by the system architect have contributed to faster product development and time-to-market.
Resource optimization: Assess how architectural decisions have led to better resource utilization, whether regarding hardware, cloud services, or personnel.
Impact on productivity: Analyze the impact of architectural improvements on the productivity of engineering teams.
Measuring success should not be a one-time activity. Adopting a continuous improvement approach is crucial, wherein feedback from stakeholders, teams, and customers is regularly collected and incorporated into the system architect’s strategies.
Feedback loops enable the system architect to adjust their approach based on real-world experiences and emerging challenges. This will help protect the organization against a gatekeeper or an ivory tower architect, which would be antithetical to the role’s intention.
Considerations for Implementation
Differentiating from EMs and Senior/Staff/Principal Engineers
While engineering managers (EMs) and engineers are usually involved in making architectural decisions, their focus is typically on the domain or squad they operate in. The system architect’s distinctiveness lies in their primary focus on enabling effective cross-squad collaboration and communication, particularly regarding cross-cutting technical implications.
Reporting structure
A role like a system architect often reports directly to engineering leadership, offering broad oversight and visibility across multiple teams. As such, it may be positioned under a Director or VP, or above, depending on the organization’s hierarchy.
Determining the number of architects
Given the depth of domain knowledge required, complex domains may require experienced architects. Hiring for this role may entail identifying existing engineers with the right skills and interest in stepping into the architect role. This may affect the pace of filling the role based on the current team’s availability and skills.
In Closing
In conclusion, I hope this exploration helps gives you a better sense of how this role could be introduced and the benefits it could bring.
I’ll leave you with this timeless video by KRAZAM. Enjoy!