29 May 2017

Recently I’ve been shopping around for a framework to replace KnockoutJS in an existing application. While KO has served it’s purpose well, over the years it hasn’t been maintained very actively and has largely failed to keep up with the newer JS frameworks in terms of features and community adoption.
After doing some research to find it’s replacement, I settled on VueJS. It seemed to be most aligned with Knockout’s MVVM pattern while at the same time being modular and extensible enough to serve as a complete MVC framework if needed using its official state management & routing libs. Above all, it seems to have a flourishing community which is important when it comes to considering a framework.
So as a KnockoutJS developer, let’s go through some of the most familiar aspects of the framework and see how it translates to VueJS.
Viewmodel
In KO, the VM is can be as simple as a object literal or or a function. Here’s a simple example:
var yourViewModel = function(args) {
this.someObv = ko.observable();
this.someObv.subscribe(function(newValue) {
//...
});
this.computedSomeObv = ko.computed(function() {
//...
});
this.someMethod = function(item, event) {
//...
}
};
Usage:
ko.applyBindings(new yourViewModel(someArgs), document.getElementById("element_id"));
VueJS has a very similar concept although the VM is always an object literal passed into a Vue instance. It also provides much more structure and richer event model. Here’s a VM stub in VueJS:
var yourViewModel = new Vue({
data: {
someKey: someValue
},
watch: {
someKey: function(val) {
// Val has changed, do something, equivalent to ko's subscribe
}
},
computed: {
computedKey: function() {
// Return computed value, equivalent to ko's computed observables
}
},
methods: {
someMethod: function() { ... }
},
created: function () {
// Called synchronously after the instance is created.
},
mounted: function () {
// Called after the instance has just been mounted where el is replaced by the newly created vm.$el
},
updated: function () {
// Called after a data change causes the virtual DOM to be re-rendered and patched.
},
destroyed: function () {
// Called after a Vue instance has been destroyed
},
});
I didn’t list all the event hooks in that example for brevity. I recommend checking out the this lifecycle diagram to get the full picture.
VueJS also offers an interesting way to organize and share common code across VMs using something called Mixins. There are certain pros and cons of using a Mixin vs just a plan old JS library but it’s worth looking into.
Usage:
yourViewModel.$mount(document.getElementById("element_id"));
Something to note about the syntax above, it is entirely optional. You can also set the value of the el attribute in your VM to #element_id and skip explicitly calling the mount function.
Bindings
The concept of bindings is something KO developers are very familiar with. I’m sure throughout the course of working with KO, we’ve all created or used a lot of custom bindings. Here’s what the custom binding stub looks like in KO:
ko.bindingHandlers.yourBindingName = {
init: function(element, valueAccessor, allBindings, viewModel, bindingContext) {
// This will be called when the binding is first applied to an element
// Set up any initial state, event handlers, etc. here
},
update: function(element, valueAccessor, allBindings, viewModel, bindingContext) {
// This will be called once when the binding is first applied to an element,
// and again whenever any observables/computeds that are accessed change
// Update the DOM element based on the supplied values here.
}
};
Usage:
<span data-bind="yourBindingName: { some: args }" />
VueJS has something similar but it’s called a “directive”. Here’s the VueJS directive stub:
Vue.directive('yourDirectiveName', {
bind: function(element, binding, vnode) {
// called only once, when the directive is first bound to the element. This is where you can do one-time setup work.
},
inserted: function (element, binding, vnode) {
// called when the bound element has been inserted into its parent node (this only guarantees parent node presence, not // necessarily in-document).
},
update: function(element, binding, vnode, oldVnode) {
// called after the containing component has updated, but possibly before its children have updated. The directive’s value may // or may not have changed, but you can skip unnecessary updates by comparing the binding’s current and old values
},
componentUpdated: function(element, binding, vnode, oldVnode) {
// called after the containing component and its children have updated.
},
unbind: function(element, binding, vnode) {
// called only once, when the directive is unbound from the element.
},
})
Usage:
<span v-bind="{yourDirectiveName: '{ some: args }' }" />
As you can see VueJS offers a couple of additional life-cycle hooks, but on the most part, its very similar to KnockoutJS. So transferring old bindings into new directives isn’t too difficult.
In most cases you should be able to move everything in your init function into the inserted function. As far as the update function goes, it will largely remain the same but you can now compare the vnode and oldVnode to avoid necessary updates. And lastly, if your custom binding used the KO’s disposal callback i.e ko.utils.domNodeDisposal.addDisposeCallback you can move that logic into the unbind function.
Another thing you’ll notice is that the usage syntax is a bit different, instead of using the data-bind attribute everywhere, VueJS uses different attributes prefixed with v- for various things such as v-bind for binding attributes, v-on for binding events, v-if/for for conditionals/loops, etc.
To add to that, there is also a shorthand syntax for those which might make things confusing initially and it’s probably the biggest gotchas for devs transitioning from Knockout to Vue. So I recommend taking some time to go through the template syntax documentation.
Extenders
Another tool in KO that we are very familiar with is the concept of extender which are useful for augmenting observables. Here’s a simple stub for an extender:
ko.extenders.yourExtender = function (target, args) {
// Observe / manipulate the target based on args and returns the value
};
Usage:
<span data-bind="text: yourObv.extend({ yourExtender: args })" />
Closest thing to extenders in VueJS is the concept of “filters”, which can be used to achieve a similar objective. Here’s what a filter stub would look like:
Vue.filter('yourFilter', function (value, args) {
// Manipulate the value based on the args and return the result
});
Usage:
<span>{{ yourVar | yourFilter(args) }}</span>
Alternatively you can also call a filter function inside the v-bind attribute
<span v-bind='{style: {width: $options.filters.yourFilter(yourVar, args)}}'/>
Components
KO offers the ability to create components to help organizing the UI code into self-contained, reusable chunks. Here’s a simple component stub:
ko.components.register('your-component', {
viewModel: function(params) {
this.someObv = ko.observable(params.someValue);
},
template: { element: 'your-component-template' },
});
Usage:
<your-component params='someValue: "Hello, world!"'></your-component>
VueJS also has the ability to create components. They are a much more feature rich and have better lifecycle hooks compared to KO. They also feel more much “native” to the framework. Here’s a simple component stub in Vue:
Vue.component('your-component', {
props: ['someValue']
data: function () {
return {
someKey: this.someValue
}
},
template: '#your-component-template'
})
Usage:
<your-component someValue="Hello, world!"></your-component>
This just scratches the surface of what’s possible with components in Vue. They are definitely worth diving more into. Maybe I’ll cover them more in another post.
Mapping - One of the commonly used plugin the KnockoutJS ecosystem has been ko.mapping plugin which helps transforming a JavaScript object into appropriate observables. With VueJS, that is not needed since Vue takes care of that under the hood by walking through all the properties of a VM and converting them to getter/setters using Object.defineProperty. This lets Vue perform dependency-tracking and change-notification when properties are accessed or modified while keeping that invisible to the user.
Validation - In addition to mapping, Knockout-Validation library is another mainstay of the ecosystem. With VueJS, vee-validate is it’s popular counterpart and provides similar features out of the box.
Debugging - It’s important to have a good debugging tool for development. KnockoutJS has Knockoutjs context debugger, while VueJS offers something similar with Vue.js devtools
Lastly…
VueJS is an incredibly feature rich framework with various options for customization and code organization. It is one of the fastest growing frameworks with adoption from some big names projects such as Laravel, GitLab, and PageKit to name a few. Hopefully that will make it a good bet for the future!
I’ll leave you with this chart which pretty much sums up the story of these two frameworks:
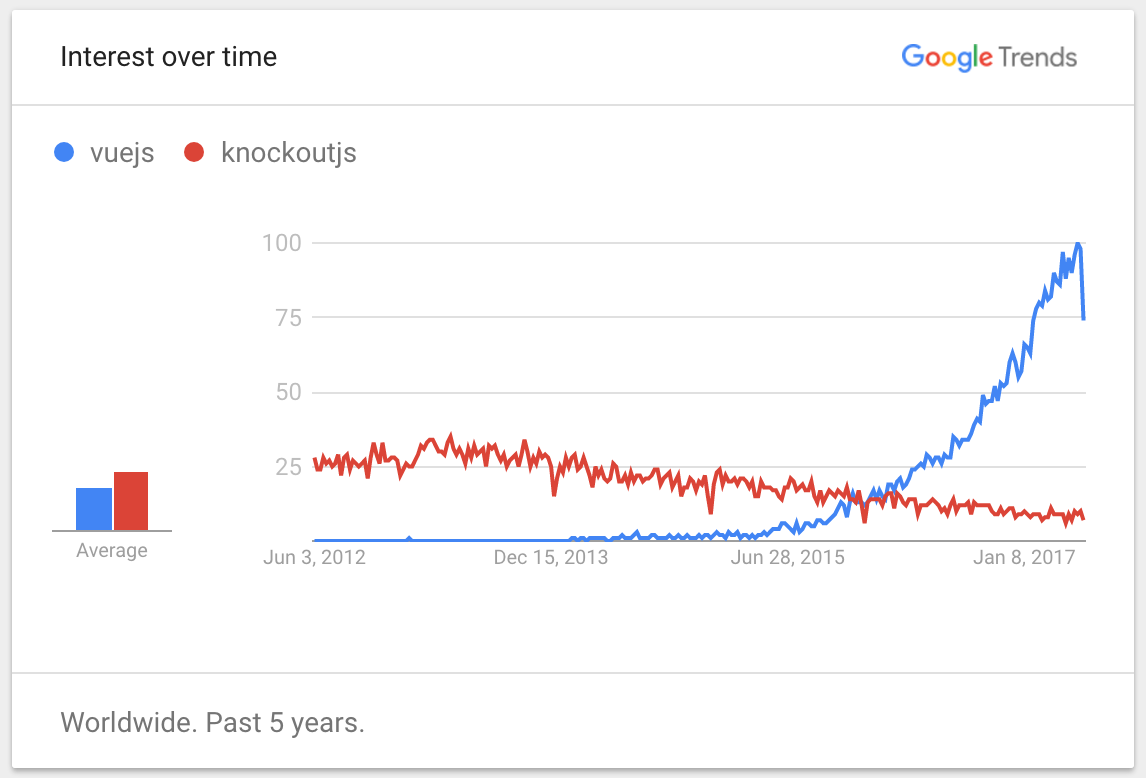
06 Mar 2017
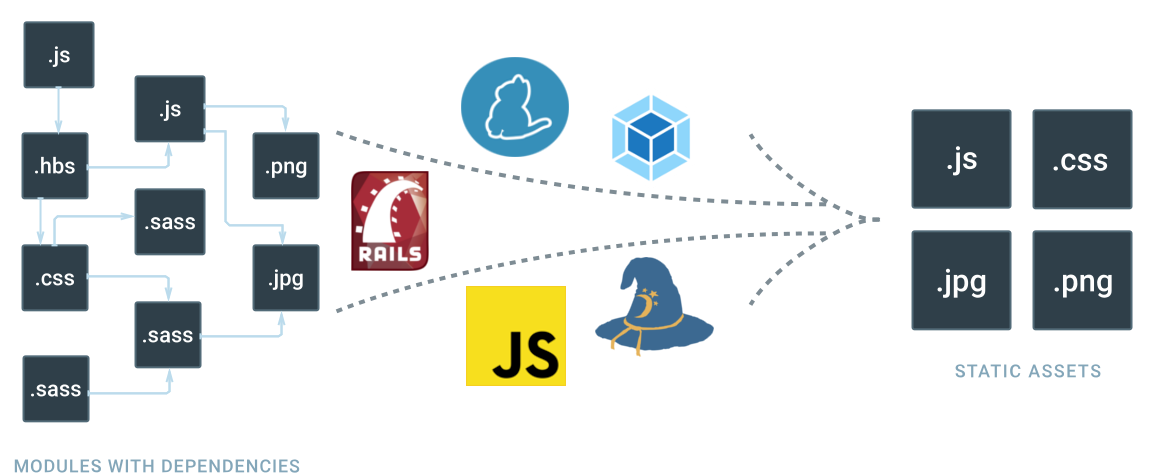
Recently I’ve been working on ways to bring modern JavaScript development practices into an existing Rails app.
As RoR developers know, Sprockets is a powerful asset pipeline which ships with Rails and thus far has JustWorked™. Although with the JavaScript ecosystem maturing in the recent years, Sprockets hasn’t been able to keep pace with the flexibility and feature set of it’s competitors. While Sprockets might have originally popularized the asset pipeline model, it was finally time to hand the reigns to it’s prodigies.
So having said that, I started searching for a viable replacement to Sprockets. My research came up with two main contenders, namely Browserify and Webpack. Here’s my experience integrating each one with a Rails app.
NodeJS
Before we can get started, let’s make sure we have NodeJS installed. I’ve found the easiest way to do so is via nvm. Rails developers will find this very similar to rvm. To install, run the following commands which will install nvm and the latest version of NodeJS:
$ curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.32.1/install.sh | bash
$ source ~/.bash_profile
$ nvm install node
$ nvm use node
Yarn
Next we’ll need a package manager. Traditionally we’d use npm but I’ve found Facebook’s yarn to be a lot more stable and reliable to work with. This is very similar to bundler. To install on Debian Linux, run the following commands or follow their installation guide for your OS:
$ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
$ echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list
$ sudo apt-get update && sudo apt-get install yarn
Browserify
Now that we have the essentials available. Let’s first try Browserify. The main objective of Browserify is to bring the ability to “require” and use NodeJS packages in the browser and bundle all their dependencies for you.
Getting Browserify integrated into Rails is surprisingly simple thanks to the browserify-rails gem. So let’s get started by adding it to our Gemfile and creating a package.json for all it’s required JS dependencies.
Gemfile
package.json
{
"name": "myapp",
"version": "0.0.1",
"license": "MIT",
"engines": {
"node": ">= 0.10"
},
"dependencies": {
"babel-preset-es2015": "^6.1.18",
"babelify": "^7.2.0",
"browserify": "~> 10.2.4",
"browserify-incremental": "^3.0.1"
}
}
Although instead of copy/pasting the dependencies from the package.json above I’d recommend using yarn add [package-name] command so you can get the latest as the versions listed above might get stale over time.
All you have to do now is run the two package managers bundle install & yarn install to finish the setup.
Usage
You can now start to define and export your own module or you can use a CommonJS compatible library and require it in your application manifest right alongside Sprockets’ require syntax:
assets/javascript/foo.js
export default class Foo {
constructor() {
console.log('Loaded Foo!')
}
}
assets/javascript/application.js
MyApp.Foo = require('./foo'); // <--- require via Browserify
//= require bar // <--- require via Sprockets
That’s pretty much all there is to it. So while getting Browserify up and running was easy, it wasn’t designed to be a complete asset pipeline replacement. You could technically set that up in conjunction with Gulp or npm scripts but it’s not something it was designed to do out of the box.
Webpack
I was hoping to go a little further than what Browserify offered with a complete asset pipeline replacement out of the box.
So having that in mind, I started looking into Webpack. It’s motto of only load what you need, when you need sounded pretty compelling.
Especially with DHH working on bringing Webpack and Yarn to Rails 5.1 which is great news and makes it a solid choice as far as future-proofing goes.
So let’s see how to get Webpack integrated right now in Rails 4.x before it becomes more formally integrated into Rails 5.
Gemfile
gem 'webpack-rails'
gem 'foreman'
package.json
{
"name": "myapp",
"version": "0.0.1",
"dependencies": {
"babel-core": "^6.9.0",
"babel-loader": "^6.2.4",
"babel-preset-es2015": "^6.9.0",
"extract-text-webpack-plugin": "^1.0.1",
"resolve-url-loader": "^1.6.0",
"stats-webpack-plugin": "^0.2.1",
"webpack": "^2.2.1",
"webpack-dev-server": "^2.3.0"
}
}
Now all you have to do is run the two package managers bundle install & yarn install to finish the setup.
Although we are not done, next let’s create a config file which will define how our Webpack asset pipeline will work.
config/webpack.config.js
'use strict';
var path = require('path');
var webpack = require('webpack');
var StatsPlugin = require('stats-webpack-plugin');
// must match config.webpack.dev_server.port
var devServerPort = 3808;
// set NODE_ENV=production on the environment to add asset fingerprints
var production = process.env.NODE_ENV === 'production';
var config = {
name: 'js',
entry: {
//Define entry points here aka manifests
'application': './webpack/javascript/application.js',
},
output: {
path: path.join(__dirname, '..', 'public', 'webpack'),
publicPath: '/webpack/',
filename: production ? '[name]-[chunkhash].js' : '[name].js'
},
resolve: {
modules: [
path.join(__dirname, '..', 'webpack', 'javascript'),
"node_modules/"
]
},
plugins: [
new StatsPlugin('manifest.json', {
chunkModules: false,
source: false,
chunks: false,
modules: false,
assets: true
})],
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: [
{
loader: 'babel-loader',
options: {
cacheDirectory: true,
presets: ['es2015'] // Use es2015-without-strict if legacy JS is causing issues
}
}
]
}
]
}
};
if (production) {
config[0].plugins.push(
new webpack.NoErrorsPlugin(),
new webpack.optimize.UglifyJsPlugin({
compressor: {warnings: false},
sourceMap: false
}),
new webpack.DefinePlugin({
'process.env': {NODE_ENV: JSON.stringify('production')}
}),
new webpack.optimize.DedupePlugin(),
new webpack.optimize.OccurenceOrderPlugin()
);
} else {
var devServer = {
host: '0.0.0.0',
port: devServerPort,
headers: {'Access-Control-Allow-Origin': '*'},
watchOptions: { //You will need this if you are a Vagrant user
aggregateTimeout: 0,
poll: 10
}
};
config.devServer = devServer;
config.output.publicPath = '//localhost:' + devServerPort + '/webpack/';
config.devtool = 'sourceMap';
}
module.exports = config;
So that’s a whole lot of configuration! But as long as you understand the Four Core Concepts of Entry, Output, Loaders & Plugins behind Webpack it will all start to make more sense.
As far as a Rails/Sprokets analogy goes, you can think of an Entry as a Manifest file and the Output as the final asset file which is produced as a result of compiling the manifest.
Everything in between is handled by Loaders which execute transformations on individual files and Plugins which execute transformations on a set of files.
Webpack offers a rich ecosystem of loaders and plugins which can perform a variety of transformations which is where the true power and flexibility of Webpack becomes apparent.
Usage
So now that we are done setting this up, let’s see how to put it in use. Unlike Browserify which only supported CommonJS modules, Webpack allows mixing and matching Harmony (ES6), AMD or CommonJS syntax for module loading:
webpack/javascript/foo.js
define ('Foo', [], function() {
return function () {
__construct = function(that) {
console.log('Loaded Foo!')
} (this)
}
}
webpack/javascript/application.js
MyApp.Foo = require('./foo');
views/layouts/application.html.haml
<%= javascript_include_tag *webpack_asset_paths('application', extension: 'js') %>
So that’s the basic setup. Next time when we start Rails, we’ll also need to start the webpack dev server which will serve the assets locally and rebuild them if they change.
For convenience, I would recommend using foreman so we can just start both Rails and Webpack with foreman start, here’s the Procfile you would need to declare before running the command:
Procfile
# Run Rails & Webpack concurrently
rails: bundle exec rails server -b 0.0.0.0
webpack: ./node_modules/.bin/webpack-dev-server --no-inline --config config/webpack.config.js
Deploy
Deploying Webpack into production is fairly staright forward. Similar to Sprockets’ rake assets:precompile task, webpack-rails gem provides rake webpack:compile task which can run in a production build script and will compile and place the assets into a location specified in our config.output option, in this case, it will be inside public/webpack folder of our Rails application.
Conclusion
So that convers the basics of setting up a modern asset pipeline in Rails. I think Browserify is great if you want to just use some ES6 features and NodeJS packages but don’t really want to necessarily overhaul the entire asset pipeline. On the other hand, Webpack is a bit more difficult to configure but it provides the most amount of flexibility and it has all the features necessary to become a complelete asset pipeline replacement.
11 Sep 2016

A couple of years ago I wrote about how to setup a local development environment using Vagrant. While Vagrant has worked out great, containerization with Docker has become all the rage. So I decided to take it for a spin to see what all the fuss is all about. I’m going to use an existing Rails app as my test subject.
Requirements
So before we get started, here’s what you’ll need to install:
Folder structure
Here’s an overview of the folder structure we’ll be creating. We’ll store our bundle, Postgres data and the web app itself on our host. We’ll also symlink the keys folder to our SSH keys: ln -s ~/.ssh/ keys
I’ll get more into the advantages of doing so further along in this post.
myapp-dev-box/
├── Dockerfile
├── docker-compose.yml
├── docker-sync.yml
├── myapp/
├── bundle/
├── pgdata/
└── keys/ -> ~/.ssh/
Dockerfile
Base
First thing we’ll do is create a Dockerfile which will be our starting point inside an empty dir called myapp-dev-box. Since this is for a Rails project, we’ll base this container off the official Ruby image on Docker Hub which you can think of as GitHub for containers.
Dependencies
Next we’ll install some dependencies that we need for the web app. Notice we will run this as a single command. Reason being, Docker caches the state of the container after each command into an intermediate container to speed things up. You can read a bit more about how this works here.
So if we need to add or remove a package, it’s recommended to re-run the entire step including apt-get update to make sure the entire dependency tree is updated.
RUN apt-get update && apt-get install -y \
build-essential \
wget \
git-core \
libxml2 \
libxml2-dev \
libxslt1-dev \
nodejs \
imagemagick \
libmagickcore-dev \
libmagickwand-dev \
libpq-dev \
ffmpegthumbnailer \
&& rm -rf /var/lib/apt/lists/*
SSH Keys
Now let’s create a folder for our app and a folder to store the SSH keys. The SSH keys are needed to checkout private repositories as part of the bundle install step inside the container.
Alternatively, you can make use of a build flow tool like Habitus to securely share a common set of keys and destroy them later in the build process. You can read more about it here. It supports many different complex build flows making it ideal for production use. Although it adds more complexity than we need just for a development environment so I’ve dediced against using it here.
You can also always create a separate set of SSH keys (without password) and place them in the same folder as the Dockerfile to be used within the container. Although this approach is a lot less secure as those keys would essentially become part of the container cache and could be exploited if someone gets hold of the image history. I wouldn’t recommend it.
Feel free to skip this step altogether if your Gemfile doesn’t reference any private repositories.
We’ll also add Github and BitBucket domains to the known hosts file to avoid first connection host confirmation during the build process.
RUN mkdir /myapp
RUN mkdir -p /root/.ssh/
WORKDIR /myapp
RUN ssh-keyscan -H github.com >> ~/.ssh/known_hosts
RUN ssh-keyscan -H bitbucket.org >> ~/.ssh/known_hosts
Bundle
Generally, we would copy Gemfile.* and run bundle install as a separate step into our Dockerfile so it can be run once and cached during subsequent runs.
Although that has some downsides especially for a development environment. First and foremost, the bundle would have to be rebuilt from scratch every time the Gemfile is changed which could get frustrating if it’s changed frequently.
Since I was primarily focused on a development environment and wanted to make this setup process as frictionless as possible for new devs, I decided to set it up in a way where the state of our bundle can be persisted after running it once even after we shut down the container and start it back up, just like it would on a VM or a local machine. And it would utilize the same SSH keys that are already present on the developer’s machine.
To make that happen, we will go ahead and point the GEM_HOME to a root folder called bundle which will be synced from the host. We’ll also update the bundle configuration to point to that path.
ENV GEM_HOME /bundle
ENV PATH $GEM_HOME/bin:$PATH
RUN gem install mailcatcher
RUN gem install bundler -v '1.10.6' \
&& bundle config --global path "$GEM_HOME" \
&& bundle config --global bin "$GEM_HOME/bin"
docker-compose.yml
Now that we have setup our base app container, it’s time to build and link a couple of supporting containers to run our app. Docker Toolbox includes a great tool called docker-compose (previously known as fig) to help us do just that.
Let’s start by defining which services we want to run, we’ll split our app into a db, redis, web and job services. For db and redis services, we’ll use the official Postgres and Redis images provided by Docker Hub without any custom changes. For job and web services, we’ll instruct it to build the image from the Dockerfile which we just created in the current directory in the previous section.
version: '2'
services:
db:
image: postgres
volumes:
- ./pgdata:/pgdata
environment:
POSTGRES_DB: myapp_development
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password4postgres
PGDATA: /pgdata
redis:
image: redis
web:
build: .
command: bundle exec rails server --port 3000 --binding 0.0.0.0
volumes_from:
- container:myapp-web-sync:rw
- container:myapp-bundle-sync:rw
volumes:
- ./keys:/root/.ssh/
ports:
- "3000:3000"
environment:
REDIS_URL: redis://redis:6379
links:
- db
- redis
job:
build: .
command: bundle exec sidekiq
volumes_from:
- container:myapp-web-sync:rw
- container:myapp-bundle-sync:rw
volumes:
- ./keys:/root/.ssh/
ports:
- "6379:6379"
environment:
REDIS_URL: redis://redis:6379
links:
- db
- redis
volumes:
myapp-web-sync:
external: true
myapp-bundle-sync:
external: true
Most of the configuration under each service instance is pretty self-explanatory but there are a couple of interesting things to note. First, under the web and db instance, you’ll notice we have a links section which tells docker compose that these two services depend on the db and redis services. So docker compose will be sure to start the linked services before it starts web or db.
Second, you’ll notice we have a volumes and volumes_from sections. volumes is the native docker syntax for mounting a directory from the host as a data volume. While this is super useful, it tends to be very slow! So for now, we are mostly going to limit using it for sharing the database and the SSH keys. For things that are most disk I/O intensive, we’ll define external volumes in volumes_from section which will utilize a gem by Eugen Mayer called docker-sync. It will give us the ability to use rsync or unison which should significantly boost performance.
For that, we’ll need to define yet another configuration file in which we will define what myapp-web-sync and myapp-bundle-sync volumes will do. As their name suggest, we’ll use each of them to sync our web project files and the bundle respectively. Note, each sync project will have to have it’s own unique port.
docker-sync.yml
syncs:
myapp-web-sync:
src: './myapp'
dest: '/myapp'
sync_host_ip: 'localhost'
sync_host_port: 10872
myapp-bundle-sync:
src: './bundle'
dest: '/bundle'
sync_host_ip: 'localhost'
sync_host_port: 10873
Showtime
Assuming you have your web project cloned into myapp-dev-box/myapp let’s go through the following steps:
Install the bundle
host $ docker-compose run web bundle install
Note we will only have to do this once, since we have the bundle state shared between our app and job services using a docker-sync volume. We only need to re-run this if/when the Gemfile changes.
Run the migrations
host $ docker-compose run web rake db:migrate
Again like the previous command, this will only need to be run initially and when there are changes thereafter since the state of the database is persisted on the host as well.
Start
This command is a helper which basically starts the sync service like docker-sync start and then starts your compose stack like docker-compose up in one single step.
host $ docker-sync-stack start
If everything was configured correctly, you should now be able to access your app on http://localhost:3000
Stop
Once you are done, you can call another helper which basically stops the sync-service like docker-sync clean and also remove the application stack like docker-compose down
host $ docker-sync-stack clean
That’s a wrap. Let me know if you run into any unexpected issues.
17 Jul 2016
It has been an interesting journey over the last decade or so building software for the web. The skills and techniques needed to get the job done have evolved drastically along with the platform itself. What used to be a solo “web master” role describing someone who put up a five page site on a shared hosting provider has now expanded into professional team sport with a much broader spectrum of roles comprising of font-end, back-end, devops, full-stack, among many others.
Given that evolution, it’s interesting to think about what the underlying skills & technologies are that make up those roles and where do we draw the domain boundaries for each of them.
So let’s start at the top of the stack with front-end developer’s role. What are some of the skills they are expected to have?
Front-end

Generally I’ve come across two types of front-end developers. Ones who are more focused on the UI/UX design aspects of the front-end vs the ones who are more focused on making those elements function. Of course then there are those who do both but they are a rare breed.
Design focus
- UI design & wire-framing — PhotoShop, Illustrator, Sketch, etc
- HTML and related templating engines — HAML, Jade, Mustache, etc
- CSS and it’s preprocessors — SASS or LESS
- Accessibility & browser compatibility quirks
Development focus
With the last bullet point, the lines are already starting to blur as we transition to the back-end
Back-end

Again the last bullet point bleeds into DevOps as it involves some understanding of networking fundamentals, memory management, processes/threads, etc
DevOps

- Cloud & PaaS environments — AWS, Heroku, etc
- Virtualization & containerization — Docker, Vagrant, OpenStack, etc
- Provisioning & orchestration — Chef, Puppet, Ansible, etc
- Continuous integration & delivery — Jenkins, TeamCity, etc
- Logging & monitoring — Nagios, Monit, NewRelic, ELK, etc
- Security & hardening — Tripwire, Snort, Netcat etc
Full-stack

That covers some common skills that are part of that holy trinity of the web stack although its by no means a exhaustive list. Now of course not everyone can see their skills perfectly fitting in one or more of those buckets. Depending on the organization & project, roles tend to vary slightly.
Engineers who can transcend those three role boundaries fall in the full-stack category. They are able to learn and keep up with most of the major developments in those areas with varying degree of focus depending on the task at hand.
With the rise of NodeJS and isomorphic application architecture this is something that will become more and more common.
10x / Ninja / RockStar

There are some skills that are shared between the those roles which are not usually explicitly required but probably end up determining if an engineer is given the mythical 10x / Ninja / RockStar label. Of course those labels are thrown around quite loosely and even an existence of such a thing is hotly debated but let’s say that’s a thing, what would or should it mean? Maybe some of these skills would be a start:
- Proficiency in source management with modern DVCSs like git, hg, etc
- Leveraging text editors/IDEs such as Vi, Emacs, SublimeText, Atom, etc to maximize their efficiency
- Ability to smartly prioritize and manage their tasks
- Ability to gather requirements from relevant stake holders and ask the right questions
- Project planning and estimation
- Continuing education
- Soft skills / people skills
That’s all for now. Would love to hear your thoughts about this. Is this is a good primer or is it missing some more basics? What has been your experience in the industry?
20 Mar 2016
For sites using a SPA (Single Page Application) architecture on the client-side, it’s difficult to come up with an alternative to window.onbeforeunload event which is provided by the browser. When the client is merely switching different views and not actual pages, there is no window.onbeforeunload event to tap into.
So what do you do if you want to prevent users from navigating away from a certain view using the back-button? I’m going to talk about strategy which will allow us to mimick behavior offered by window.onbeforeunload. It basically relies on adding a random hash to the URL and then tapping into the window.onhashchange event when that hash is removed.
Here’s how it works:
TL;DR: Scroll to the bottom for a link to the demo
First when you load a view from which you want to prevent your users from navigating away with the back-button, call a function to add a random hash to the URL:
self.addRandomHash = function() {
// This will harmlessly change the url hash to "#random",
// which will trigger onhashchange when they hit the back button
if (_.isEmpty(location.hash)) {
var random_hash = '#ng-' + new Date().getTime().toString(36);
// Push "#random" onto the history, making it the most recent "page"
history.pushState({navGuard: true}, '', random_hash)
}
};
You’ll notice that we prefixed our random hash with #ng- and added a navGuard attribute to the history, this is done mainly so we can detect navigation events related to our nav guard logic and prevent things like tracking page events in Google Analytics or initializing 3rd party modules, etc.
So now you want to subscribe to the hash change event. When it changes, show a native confirm dialog similar to what you see with the window.onbeforeunload event:
$(window).off('hashchange.ng').on('hashchange.ng', function(event) {
if (_.isEmpty(location.hash)) {
var msg = 'Are you sure you want to navigate away from this screen? You may lose unsaved changes.';
var result = confirm(msg);
if (result) {
//Go back to where they were trying to go
//Only go back if there is something to go back to
if (window.history.length > 2) {
window.history.back();
}
} else {
// Put the hash back in; rinse and repeat
window.history.forward();
}
}
});
//While we are at it, also throw in the traditional beforeunload listener to guard against accidantal window closures
$(window).off('beforeunload.ng').on('beforeunload.ng', function(event) {
return msg;
});
So what you see there is, if they confirm the prompt, we take them back to the previous page if there is one. window.history.length should be greater than 2 because we have to count the current URL without the hash and the previous URL with the hash.
Also another thing you want to make sure is to not show that prompt when they are navigating within the app using JavaScript i.e switching views. So disable the listener if they just clicked on anything other than the browser’s back/forward button:
$('a').not('a,a:not([href]),[href^="#"],[href^="javascript"]').mousedown(function() {
$(window).off('beforeunload.ng');
});
That’s it. It’s a bit of a hack but that’s the best I could could think of. I’d love to hear of any other techniques that you guys are using.
Demo: https://jsfiddle.net/qz2p9b63/3/ (To test, hit your browser’s back button)
