06 May 2018
With the latest major Webpack release (version 4.x), we are at a point where you don’t need a config to get started. It is optimized by default (#0CJS!). So plugins that had to be manually added and configured like CommonsChunkPlugin,UglifyjsWebpackPlugin, etc are automatically instantiated by Webpack under the hood which makes life easier!
Although there are a few things we can still do to make sure we are getting the most out of Webpack. Let’s go through them one by one.
Mode
Webpack 4 comes with two modes: production and development. Running webpack with the flag --mode development|production or setting that in the config file enables bunch of optimizations by default:
| Option |
Description |
development |
Provides process.env.NODE_ENV with value development. Enables NamedChunksPlugin and NamedModulesPlugin. |
production |
Provides process.env.NODE_ENV with value production. Enables FlagDependencyUsagePlugin, FlagIncludedChunksPlugin, ModuleConcatenationPlugin, NoEmitOnErrorsPlugin, OccurrenceOrderPlugin, SideEffectsFlagPlugin and UglifyJsPlugin. |
So no need to manually include those plugins or set the NODE_ENV using the DefinePlugin, that’s all taken care of when using mode.
By the way, if you still want to pass custom params to the UglifyJsPlugin, which I found myself wanting to, you can do so by installing it: npm install uglifyjs-webpack-plugin --save-dev and then specifying your custom params in the Webpack config:
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
if (process.env.NODE_ENV === 'production') {
config.optimization = {
minimizer: [
new UglifyJsPlugin({
parallel: true,
cache: true,
sourceMap: true,
uglifyOptions: {
compress: {
drop_console: true
}
},
}),
],
};
}
That will basically override Webpack’s default minimizer instance with your own so you have full control over it.
That config will make sure uglifier runs in parallel mode, caches output to reuse in the next build, generates source maps and suppresses comments in the console when running in production mode. You can find the full list of available options here.
Hashes
By default, Webpack will not add cache busting hashes to the output filenames (eg, index.7eeea311f7235e3b9a17.js). So your users might not get the latest code the next time you do a release which could result in a lot of strange behavior and bugs.
So in order to refresh your assets after every build, you can add the hash in the filename:
module.exports = {
entry: {
vendor: './src/vendor.js',
main: './src/index.js'
},
output: {
path: path.join(__dirname, 'build'),
filename: '[name].[hash].js'
}
};
Although if you think about it, that seems a bit heavy-handed. What if there are no changes in your vendor.js, it would be nice if Webpack was smart and only updated the hash of chunks that have changed. That way the client doesn’t have to download all the assets again every time we push out a new build even if nothing has changed.
In order to ensure that happens, Webpack provides chunkhash. Chunkhash is based on the contents of each entry point rather than the entire build. Using that is just as easy:
module.exports = {
...
output: {
...
filename: '[name].[chunkhash].js'
}
};
This will make sure we are getting the best of both worlds. When a new release goes out, the client will fetch the updated files while still using the cached version of the files that haven’t changed.
Babel
Transpiling
Since not every browser supports ES6/7/Next features, navigating what would work and wouldn’t on browsers quickly becomes a minefield:
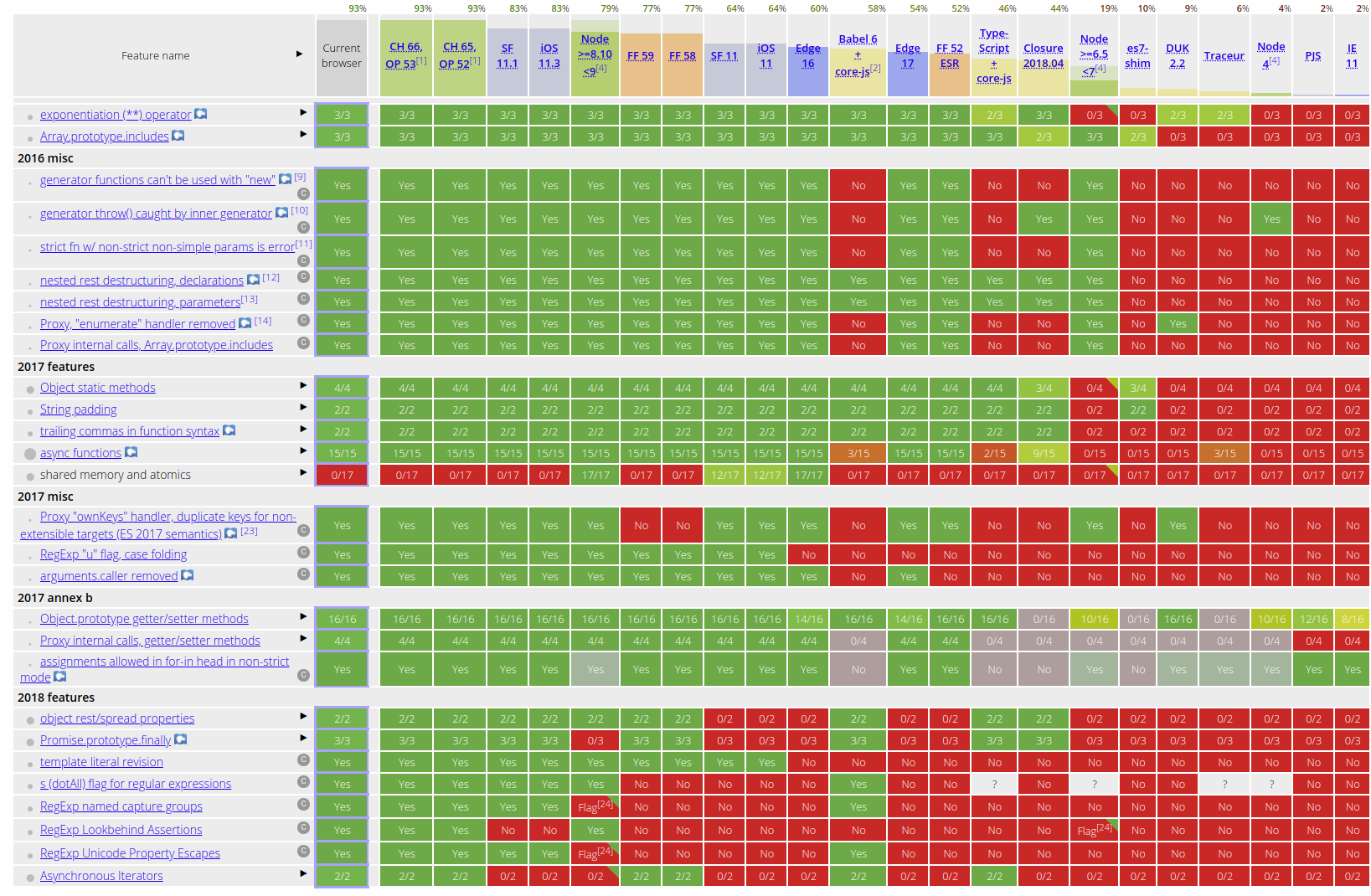
So that’s where Babel comes in. It provides some amazing plugins that make writing modern JavaScript a breeze by transpiling (converting) modern JS into something that will work on every browser we specify.
You’d set that up by installing: npm install babel-core babel-loader babel-preset-env --save-dev
Now you can tell Babel which browsers we want to target in plain English (using browserslist syntax) in .babelrc at the root of your project folder:
{
"presets": [
["env", {
"targets": {
"browsers": ["last 2 versions", "safari >= 9"]
}
}]
]
}
This is possible using the env preset which automatically determines the Babel plugins you need based on the environments you’ve specified.
Lastly, we’ll want to let Webpack know what we want to transpile all our JavaScript with Babel:
module.exports = {
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: {
loader: "babel-loader",
options: {
cacheDirectory: true
}
}
}
]
}
};
Now you can use all the latest JavaScript syntax worry-free as Babel will take care of browser compatibility.
Dynamic imports
So the next advantage of using Babel is performance related. We can use it’s dynamic import plugin to load large dependencies asynchronously only when you need them aka lazy loading. This can make a dramatic impact on the size of your entry point file since Webpack doesn’t have to load the entire dependency tree at once.
You’d set that up by installing: npm install syntax-dynamic-import --save-dev and then adding that to your .babelrc
{
"presets": [
...
]
"plugins": ["syntax-dynamic-import"]
}
So now a module that looks like this:
import foo from 'foo'
import bar from 'bar'
import baz from 'baz'
const myfun = () => {
//Do something with the modules here
}
can be converted to this:
const myfun = () => {
return Promise.all([
import('foo'),
import('bar'),
import('baz'),
]).then(([foo, bar, baz]) => {
//Do something with the modules here
});
};
Webpack will recognize those dynamic imports and code split those into separate chunks. They will be loaded async once myfun is called at runtime. This will make sure our initial chunk size remains small and the client doesn’t have to download resources that it may not even need.
Side note, if you are using Vue this is supported out of the box with Async Components but of course, if you are dealing with a large app with various frameworks that alone will not suffice so you will need a generic solution like this.
Preload
Now that we have optimal code-splitting, one downside is that the client still has to load those dependencies at runtime potentially slowing down the responsiveness of your app. So in the example above, when we call myfun, the client first has to load foo, bar and baz before it can execute the function.
What if we could preload those dependencies in the background so by the time we call myfun those dependencies are already available and ready to go? That’s where the preload plugin comes in.

It uses the Preload web standard to declaratively let the browser know that a particular resource will be needed soon so it can start loading it.
You’d set that up by installing: npm install --save-dev preload-webpack-plugin html-webpack-plugin and then adding that to your Webpack config:
const PreloadWebpackPlugin = require('preload-webpack-plugin');
const HtmlWebpackPlugin = require('html-webpack-plugin')
plugins: [
new HtmlWebpackPlugin(),
new PreloadWebpackPlugin({
rel: 'preload',
include: 'asyncChunks'
})
]
That’s it! Now all our async chunks will be added to our HTML and preloaded like this:
<link rel="preload" as="script" href="chunk.31132ae6680e598f8879.js">
<link rel="preload" as="script" href="chunk.d15e7fdfc91b34bb78c4.js">
<link rel="preload" as="script" href="chunk.acd07bf4b982963ba814.js">
As of Webpack 4.6+, this comes built in where you can manually specify which dependencies you want to preload or prefetch using inline import directives which Webpack will automatically output as resource hits without the need to install the plugins I mentioned above.
So all you’d need to change in the import statements from above:
import("foo");
import("bar")
would be this:
import(/* webpackPrefetch: true */ "foo");
import(/* webpackPreload: true */ "bar")
So it comes down to a matter of preference, whether you want to manage your preload preference from the config file for the entire project using the preload plugin or if it’s something you want to leave up to individual developers and let them decide which dependencies should be preloaded/prefetched in which case no need to install anything special.
Lastly, you’ll want to carefully consider if you want to use prefetch or preload. It will depend on the resource and the application context. I’ll point you to this excellent write-up by Addy Osmani to understand the subtle differences between the two. But as a general rule:
Preload resources you have high-confidence will be used in the current
page. Prefetch resources likely to be used for future navigations
across multiple navigation boundaries.
Analyzers
Now that we’ve looked at some ways at optimizing our Webpack setup, we’ll want to keep an eye on the bundle as we add more code and dependencies to make sure it’s still at its optimal state. My two favorite tools for doing that are:
Webpack Bundle Analyzer

You’d set that up by installing: npm install --save-dev webpack-bundle-analyzer and then adding that to your Webpack config:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
if (process.env.NODE_ENV !== 'production') {
config.plugins.push(new BundleAnalyzerPlugin())
}
Next time when you start the webpack-dev-server in development mode, you can navigate to http://localhost:8888 to see the bundle visualization like above
Webpack Monitor

This is my second favorite tool, it presents the same information as Webpack Bundle Analyzer but in a slightly different way in addition to providing a way to monitor bundle history over time.
You’d set that up by installing: npm install --save-dev webpack-monitor and then adding that to your Webpack config:
const WebpackMonitor = require('webpack-monitor');
// ...
plugins: [
new WebpackMonitor({
capture: true, // -> default 'true'
target: '../monitor/myStatsStore.json', // default -> '../monitor/stats.json'
launch: true, // -> default 'false'
port: 3030, // default -> 8081
excludeSourceMaps: true // default 'true'
}),
],
You could run this in development like the previous plugin or maybe also run this for production builds and export the output somewhere to so you can analyze how your production bundle has changed over time.
Conclusion
That’s all folks! Hopefully, with all these techniques you are able to significantly cut the bundle size and improve performance. Let me know how it goes. Are there any other techniques that I missed? Leave a comment below!
08 Apr 2018
While Ethereum has been the platform of choice for writing dApps, Stellar arguably has really low transaction fees and is much faster than other blockchains (including Ethereum).
So I began to wonder what it would look like to actually build a decentralized version of a forum like HackerNews or Reddit using the Stellar blockchain. Here’s the big picture of how I envisioned it to work:
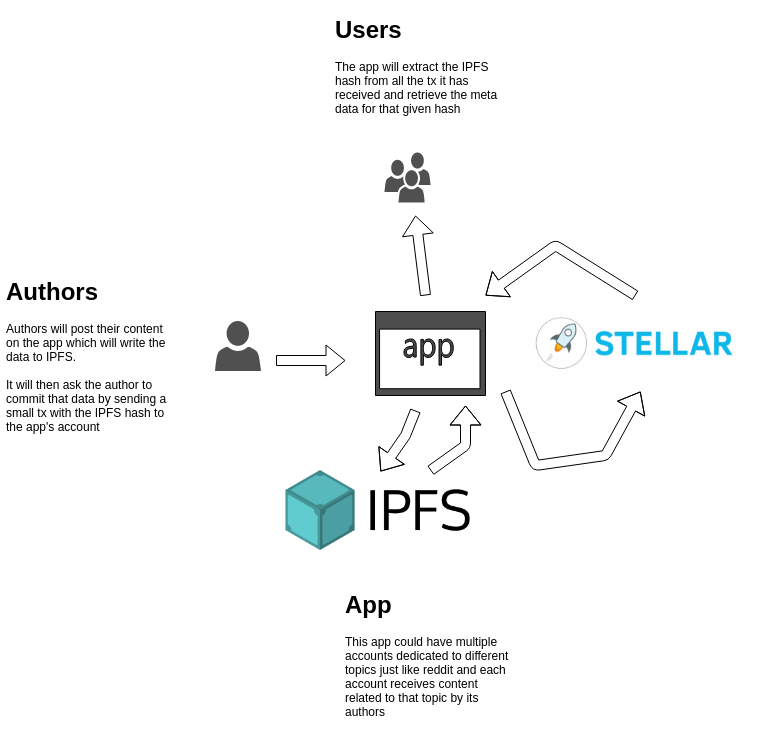
Let’s see how we would go about implementing that.
First, we need to create an account on the Stellar testnet. What’s a testnet? In the simplest terms, it’s a blockchain intended for testing where you don’t incur any real fees. In this case, we’ll load up our test account with 10k fake lumens for testing.
Next, we will build a small JavsScript client which will allow the user to submit their post on the app.
We could directly take this post and have the user send it to our app’s account by putting it in the transaction’s memo field. Although it turns out Stellar’s transaction only allows limited memo formats - Text (UTF-8 string of up to 28 bytes), ID (Unsigned 64-bit integer) or Hash (32-byte hash in hex format). So storing a large amount of text or JSON is out of the question.
Send it to IPFS
That’s where IPFS comes in - a P2P protocol and network designed to store and share content in a distributed file system across all devices (think of it as a love child of git and BitTorrent).
We would take that data and store it in a JSON object in the IPFS.
import ipfsAPI from 'ipfs-api'
// I'm just using an IPFS gateway here for testing but in a real-world setting, we would run our own IPFS node so we can persist data
const ipfs = ipfsAPI({ host: 'ipfs.infura.io', port: 5001, protocol: 'https' });
const post = JSON.stringify({title: 'So exited!!!', content: 'This is my first post on the blockchain!', username: 'h4ck3r'})
const buffer = Buffer.from(post);
ipfs.files.add(buffer, { pin: false }, (err, ipfsHash) => {
console.log(ipfsHash[0].path) // => QmV3C3HFE8824KWYTMq5fbZyF93GTMz5W7h3uBG1oVZCv8
});
Now we have a hash small enough to send in the memo field. Although looks like there might be another issue. IPFS represents the hash of files and objects using a Multihash multiformat with Base58 encoding. The prefix Qm corresponds to the algorithm (SHA-256) and length (32 bytes) used by IPFS.
So it looks like we are not going to be able to add this in our transaction’s Text field which only allows strings of up to 28 bytes nor are we able to use the Hash field which only allows 32-byte hash.
So we’ll have to write a function that converts this IPFS hash back to 32 byte hash in hex format:
import bs58 from 'bs58'
this.getBytes32FromIpfsHash = (ipfsListing) => {
// Decode the base58 string and then slice the first two bytes
// which represent the function code and it's length, in this case:
// function:0x12=sha2, size:0x20=256 bits
return bs58.decode(ipfsListing).slice(2).toString('hex')
}
Add it on the Blockchain
Now that we have the right hash to store in the memo field, we’ll have to figure out how to actually send this transaction. One option is to prompt the user to make use of MetaPay which is a Chrome extension wallet for Stellar (kind of like MetaMask for Stellar Lumens). Once they have MetaPay installed, we can just setup a URL like this:
<a ref='savePost' data-meta-pay
href="https://stellar.meta.re/transaction?to=[address]&amount=1&memo=[txMemo]"
target="_blank" >Save Post</a>
Now if we put it all together, the submit post logic would look something like this:
import StellarSdk from 'stellar-sdk'
// Add the post data to IPFS
this.submitPost = (post) => {
const buffer = Buffer.from(post);
ipfs.files.add(buffer, (err, ipfsHash) => {
this.txMemo = this.getBytes32FromIpfsHash(ipfsHash[0].path)
this.refs['savePost'].click() // This will open the MetaPay popup
this.confirmPayment(this.txMemo) // Listen to see if the transaction went through
});
}
// Check to see if the transaction went through
this.confirmPayment = (ipfsHash) => {
const server = new StellarSdk.Server('https://horizon-testnet.stellar.org');
server.transactions().forAccount('OUR_ACCOUNT_ID').cursor('now').stream({
onmessage: (transaction) => {
if(transaction.memo == ipfsHash) {
// Yes, it made it on the blockchain!
transaction.operations().then((ops) => {
var payment = ops._embedded.records[0];
if(parseInt(parseFloat(payment.amount)) < 1) {
console.error('Payment insufficient. Post not saved!');
} else {
this.pinIpfsListing(ipfsHash);
}
}).catch((error) => {
error.target.close(); // Close stream
console.error('Payment Error: ', error);
alert('Error confirming payment. Try again later');
});
}
},
onerror: (error) => {
error.target.close(); // Close stream
console.error('Streaming Error: ', error);
}
});
}
That will open the MetaPay popup with all the prefilled fields, we will wait and see if the user goes through with that transaction, if they do, we move to the next step.
Persist it on IPFS
// If successful, pin our post on the IPFS node
this.pinIpfsListing = (ipfsHash) => {
ipfs.pin.add(ipfsHash)
}
Notice when we added our data to IPFS, we didn’t pin it. Without pinning the post, our data will not be stored permanently on the IPFS node and will eventually be garbage collected.
So in a way that small transaction fee helps us pay for pinning the data / the cost of running an IPFS node and make sure the data is available for all users.
Read from the Blockchain & find it on IPFS
Now when other users visit the app, we will pull all the transactions posted to this app’s account, grab the memo field, encode it back to Base58 and pull the data from IPFS:
import StellarSdk from 'stellar-sdk'
import ipfsAPI from 'ipfs-api'
this.getIpfsHashFromBytes32 = (bytes32Hex) => {
// Add our default ipfs values for first 2 bytes:
// function:0x12=sha2, size:0x20=256 bits
const hashHex = "1220" + bytes32Hex
const hashBytes = Buffer.from(hashHex, 'hex');
const hashStr = bs58.encode(hashBytes)
return hashStr
}
const server = new StellarSdk.Server('https://horizon-testnet.stellar.org');
const ipfs = ipfsAPI({ host: 'ipfs.infura.io', port: 5001, protocol: 'https' });
let posts = [];
server.transactions()
.forAccount('OUR_ACCOUNT_ID')
.order('desc')
.call()
.then((page) => {
page.records.forEach(record => {
if (record.memo) {
const ipfsListing = this.getIpfsHashFromBytes32(record.memo)
ipfs.files.get(ipfsListing, function (err, files) {
files.forEach((file) => {
const post = file.content.toString('utf8')
posts.push(post) // Show this to the user
})
})
}
});
});
Decentralization
This architecture makes sure our data is decentralized but what about the app itself? If the app goes down, users could write another client that can read from that account’s blockchain and pull the corresponding data from IPFS.
Although we could go one step further and actually store the client code on the blockchain as well by utilizing the manageData account operation.
Something like this could be part of the build / deploy chain for the app, so everytime a new version is released, it’s also added to the blockchain:
import fs from 'fs'
this.publishClient = () {
const code = fs.readFileSync('my_project/client.js');
ipfs.files.add(buffer, (err, ipfsHash) => {
const server = new StellarSdk.Server('https://horizon-testnet.stellar.org');
server.loadAccount('OUR_ACCOUNT_ID').then((base) => {
const tx = new StellarSdk.TransactionBuilder(base);
const data = {name: 'v1.0.0', value: ipfsHash[0].path};
tx.addOperation(StellarSdk.Operation.manageData(data));
var builtTx = tx.build();
builtTx.sign(StellarSdk.Keypair.fromSecret('OUR_ACCOUNT_SECRET'));
return server.submitTransaction(builtTx);
});
});
}
Although something to keep in mind, each DataEntry increases the minimum balance needed to be held by the account. So we might want to only maintain the last version or the last couple of versions of the client codebase on the account. But that should suffice to make our demo app more or less decentralized.
Conclusion
This was an interesting thought experiment but this demo app still does not have a way to manage comments, upvotes, etc since we are somewhat limited by what the Stellar platform is capable of.
To build something more advanced we’d need to build it on a true dApp platform like Ethereum or NEO that have all the necessary tooling to make that happen.
But with the recent controversy of Facebook data and user privacy, it’s definitely time to think about how to build social apps that are decentralized.
There’s a lot of interesting work done in this space with projects like Datawallet, Blockstack, Akasha and others which will be interesting to follow in the coming years.
11 Feb 2018

We have all heard of the MEAN (MongoDB Express Angular NodeJS) stack or more lately the MERN (MongoDB Express React and NodeJS) stack.
There are plenty of starter kits utilizing those stacks although I was looking for something similar but with a couple of changes. I wanted to switch out MongoDB with PostgresSQL because it’s a workhorse that can do just about anything and switch out React with VueJS because I find Vue much more approachable and beginner friendly.
I didn’t find anything like that out there, so I ended up creating one myself. Lets call it the PEVN (PostgreSQL Express VueJS NodeJS) stack, I know…0 for creativity!
I spent couple of hours getting everything working like how I wanted it to. I documented the process to save the trouble for anyone looking to do the same which you’ll find below.
TL;DR - https://github.com/jesalg/pevn-starter
NodeJS
Before we can get started, let’s make sure we have NodeJS installed. I’ve found the easiest way to do so is via nvm. Rails developers will find this very similar to rvm. To install, run the following commands which will install nvm and the latest version of NodeJS:
$ curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.32.1/install.sh | bash
$ source ~/.bash_profile
$ nvm install node
$ nvm use node
Express
Easiest way to install Express is using the generator:
$ npm install express-generator -g
$ express pevn-starter
$ cd pevn-starter && npm install
VueJS
Now that we have a basic app, let’s get to the fun part. We will treat each Express view as it’s own VueJS app (MVVM pattern) which will grab the data it needs from the DOM and/or making AJAX requests to the server.
So for this example, given we have views/index.jade we will want to place it’s associated VueJS app and styles in client/css/index.css, client/js/index.js and /client/js/Index.vue such that when that Jade view is rendered, it will run the Index Vue app.
So we’ll have to tell our view in views/index.jade to load our packaged asset file:
extends layout
block content
#index(data-visitors-json="#{JSON.stringify(visitors)}")
script(src="#{webpack_asset('index', 'js')}")
link(rel='stylesheet', href="#{webpack_asset('index', 'css')}")
Our client/js/index.js will bootstrap our Index Vue app:
import Vue from 'vue'
import Index from './Index.vue'
new Vue({
el: '#index',
data: {
visitors: []
},
render (createElement) {
return createElement(Index)
},
beforeMount() {
this.visitors = JSON.parse(this.$el.dataset.visitorsJson) //Grab this data from the DOM
}
})
Our Vue app lives in client/js/Index.vue:
<template>
<div>
<h1>Hello World</h1>
<p>Welcome to PostgreSQL, Express, VueJS, NodeJS starter</p>
<p>Here are the last 10 visitors:</p>
<table>
<thead>
<th>ID</th>
<th>IP</th>
<th>User Agent</th>
</thead>
<tr v-for="(visitor, index) in visitors" :key="index">
<td></td>
<td></td>
<td></td>
</tr>
</table>
</div>
</template>
<script>
export default {
data() {
return {
visitors: []
}
},
methods: {
},
created() {
this.visitors = this.$parent.visitors; //Grab this data from the parent
}
}
</script>
Don’t worry about the logic to display the list of visitors just yet. We’ll get to that in a minute.
Webpack
In order to create a packaged index.js asset file for our view, we will need to install Webpack, VueJS and its associated dependencies:
$ npm install webpack extract-text-webpack-plugin assets-webpack-plugin babel-core babel-loader babel-preset-es2015 css-loader file-loader style-loader url-loader vue-template-compiler --save-dev
$ npm install vue express-webpack-assets webpack-dev-middleware webpack-hot-middleware
Next, let’s create webpack.config.js at the root of our project and paste the following in there:
var path = require('path')
var webpack = require('webpack')
var ExtractTextPlugin = require("extract-text-webpack-plugin");
var SaveHashes = require('assets-webpack-plugin');
var isProd = (process.env.NODE_ENV === 'production');
var config = {
entry: {
index: [
path.join(__dirname, 'client/js/index.js'),
path.join(__dirname, 'client/css/index.css')
],
},
output: {
path: path.join(__dirname, 'public/dist/'),
publicPath: '/dist/',
filename: '[name].[hash].js'
},
resolve: {
extensions: ['.js', '.vue'],
alias: {
vue: isProd ? 'vue/dist/vue.min.js' : 'vue/dist/vue.js',
}
},
module: {
rules: [{
test: /\.vue$/,
exclude: /node_modules/,
use: [{
loader: 'vue-loader'
}]
},
{
test: /\.js$/,
exclude: /node_modules/,
use: [{
loader: 'babel-loader',
options: {
presets: ['es2015']
}
}]
},
{
test: /\.svg/,
use: {
loader: 'svg-url-loader',
options: {}
}
},
{
test: /\.css$/,
loader: ExtractTextPlugin.extract({
fallback: "style-loader",
use: {
loader: 'css-loader',
options: {
minimize: true
}
}
})
},
]
},
devtool: 'eval-source-map',
plugins: [
new SaveHashes({
path: path.join(__dirname, 'config')
}),
new ExtractTextPlugin({
publicPath: '/dist/',
filename: '[name].[hash].css',
allChunks: true
}),
new webpack.HotModuleReplacementPlugin(),
new webpack.DefinePlugin({
'process.env': {
'NODE_ENV': JSON.stringify('production')
}
})
]
}
if (isProd) {
config.plugins.push(new webpack.optimize.UglifyJsPlugin());
}
module.exports = config
Our Webpack config will make sure the assets in the client folder get compiled into a compressed JS and CSS package with a cache busting hash filename.
Now we will have to let Express know that we are using Webpack and that we want to run it during start-up. So in the app.js add the following:
var webpack = require('webpack')
var webpackDevMiddleware = require('webpack-dev-middleware')
var webpackHotMiddleware = require('webpack-hot-middleware')
var webpackAssets = require('express-webpack-assets')
.
.
.
// webpack setup
if (NODE_ENV === 'production') {
app.use(express.static(__dirname + '/dist'));
} else {
const compiler = webpack(config)
app.use(webpackDevMiddleware(compiler, {
publicPath: config.output.publicPath,
stats: { colors: true }
}))
app.use(webpackHotMiddleware(compiler))
}
app.use(webpackAssets('./config/webpack-assets.json', {
devMode: NODE_ENV !== 'production'
}));
.
.
.
PostgreSQL
Lastly let’s go ahead and add pg support by installing sequelize ORM and associated dependencies:
$ npm install sequelize pg pg-hstore --save
$ npm install sequelize-cli --save-dev
$ ./node_modules/.bin/sequelize init
Running those commands will create some setup code, you will just need to update your config/config.json with the right connection info:
{
"development": {
"username": "root",
"password": null,
"database": "pevn_development",
"host": "127.0.0.1",
"dialect": "postgres"
},
"test": {
"username": "root",
"password": null,
"database": "pevn_test",
"host": "127.0.0.1",
"dialect": "postgres"
},
"production": {
"username": "root",
"password": null,
"database": "pevn_production",
"host": "127.0.0.1",
"dialect": "postgres"
}
}
Once you have that, we are ready to create our first model and run the migration:
$ ./node_modules/.bin/sequelize model:generate --name Visitor --attributes ip:string,user_agent:string
$ ./node_modules/.bin/sequelize db:create
$ ./node_modules/.bin/sequelize db:migrate
For the purpose of this example, we will just create a Visitors table which will log the user’s IP and UserAgent string every time you visit the home page and spit out the last 10 records:
var express = require('express');
var models = require('../models');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res, next) {
models.Visitor.create({
user_agent: req.get('User-Agent'),
ip: req.ip,
}).then(() => {
models.Visitor.findAll({limit: 10, order: [['createdAt', 'DESC']]}).then((visitors) => {
res.render('index', { title: 'PEVN Stack!', visitors: visitors });
})
});
});
module.exports = router;
Conclusion
With that we come full circle and close the loop. If everything worked, you should now be able to run your app on port 4000 with:
One thing you might notice is that the app will require a restart everytime you change the server code which can get pretty annoying. We can switch to using nodemon instead so the app can restart automatically when the code changes:
$ npm install --save-dev nodemon
In our nodemon.json we can configure it to restart when it detects changes to our server side logic:
{
"verbose": true,
"ignore": ["public/"],
"events": {
"restart": "osascript -e 'display notification \"App restarted due to:\n'$FILENAME'\" with title \"nodemon\"'"
},
"watch": ["routes/"],
"env": {
"NODE_ENV": "development"
},
"ext": "js jade"
}
Lastly we can update our npm start command to be nodemon app.js
There are a few more interesting things we could do which I left out for this quick start. Like for example, we could run our NodeJS server logic through Babel so we can use ES6 syntax on the server as well. I’ll look forward to pull requests for those kind of enhancements from the community! :)
12 Nov 2017
With the cryptocurrency space being white-hot I’ve been very curious and learning all that I can. What better way to understand the core concepts than to start at the root of how cryptocurrency is generated aka mining. So here’s some of what I’ve learned in the process of doing just that, hope you find it useful!
What is mining?
In the simplest terms, the act of mining serves two purposes. One, the miner is essentially providing book-keeping services for the crypto’s public ledger aka blockchain by taking recent transactions every few minutes and writing them onto a page of the ledger referred to as a “block”.
Although miners have to solve a puzzle / cryptographic function to be able to add their block to the blockchain, whoever is able to do this first, is rewarded with some crypto in exchange for their services.
This brings me to the second purpose, the crypto which is rewarded is considered “mined”. This is essentially because it is new currency that’s released to the network. All cryptocurrencies have a fixed number that is set to release to the network through this mining process.
As that unreleased currency dwindles down, miners are then incentivized by a reward attached to each transaction in the block. So the transactions that include this reward i.e transaction fee are likely to be processed faster.
Pick a currency
Now that we understand the high level concept behind mining, let’s figure out what to mine. Naturally, BTC (Bitcoin) or ETH (Ethereum) would be our obvious candidates as they are the most well known and popular currencies at the moment. Although the issue with both is the fact that they are not very profitable to mine using a basic CPU or GPUs. If you are starting out, I’m assuming that’s pretty much what you will have access to.
In most cases, the popularity of a currency has a direct correlation with it’s mining difficulty. The more miners that join the pool, the faster new pages are written on the ledger. To keep the number of pages created steady, the difficulty of the puzzle is increased at a regular interval.
So out of the top 10 currencies on coinmarketcap.com, the best candidate for CPU or GPU mining would be XMR (Monero) since it’s based on a proof-of-work algorithm called CryptoNight which is designed to be suitable for ordinary CPU and GPUs and is resistant to mining with special hardware i.e ASIC. So having said that, let’s pick XMR. If you need some more convincing, here’s a good list of why XMR is a good bet.
Setup a wallet
So the next thing we’d have to figure out is where to store the proceeds from the mining. For XMR, the options are somewhat limited since it’s still a currency in development. The best bet would be to download & install the official wallet.
Alternatively, you can setup an account in one of the online exchanges like Bittrex or Kraken and use their built-in wallet, although it’s not recommended to use that as a long term storage for large amounts of currency.
Once you have this setup, take note of your wallet’s address. We will need this in the next steps.
Join a pool
So while XMR is friendly to solo mining, the chances of earning a reward are low. So in order to boost our chances, we’ll want to share our processing power in a network of other miners. We can then earn our reward according to the amount of hashing power we contributed towards creating a block.
There are several XMR mining pools that you can choose from this list. I would recommend sticking to xmrpool.net if you are in US or moneropool.com if you are in Europe.
Both have a good balance of # of miners and the hash rate. You don’t want to join a pool with a lot of miners because your earnings can get very diluted, you’ll want to stick to a good balance between hashing power and the # of members in a pool.
Start mining
So now we are finally ready to start mining. We have two options, we can either use the CPU or the GPU to do the mining. Let’s look at both the options and how they work.
CPU
ServeTheHome has put together some awesome Docker images to make this easy. You can install Docker for your platform if you haven’t already and run this command:
For xmrpool.net:
sudo docker run -itd -e username=[YOUR_WALLET_ADDRESS] servethehome/monero_cpu_xmrpooldotnet
For moneropool.com:
sudo docker run -itd -e username=[YOUR_WALLET_ADDRESS] servethehome/monero_cpu_moneropool
GPU
Again huge thanks to ServeTheHome for providing images for Nvidia GPUs which makes GPU mining super simple without having to install CUDA dependencies on your machine.
Although what you will need to install is nvidia-docker so the Docker container can utilize your GPU.
Installation on Ubuntu should be pretty straightforward:
# Install nvidia-docker and nvidia-docker-plugin
wget -P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker_1.0.1-1_amd64.deb
sudo dpkg -i /tmp/nvidia-docker*.deb && rm /tmp/nvidia-docker*.deb
# Test nvidia-smi
nvidia-docker run --rm nvidia/cuda nvidia-smi
Checkout installation steps on their repo for other distros. Once you have that working you can spin up the Docker instance:
For xmrpool.net:
NV_GPU=0 nvidia-docker run -itd -e username=[YOUR_WALLET_ADDRESS] --name GPU0_monero servethehome/monero_gpu_nv_xmrpooldotnet
For moneropool.com:
NV_GPU=0 nvidia-docker run -itd -e username=[YOUR_WALLET_ADDRESS] --name GPU0_monero servethehome/monero_gpu_nv_moneropool
If you have multiple GPUs you will need to add NV_GPU=0 prefix as shown above and spin up additional containers for each GPU you want to target. If you only have one, you can skip the prefix and explicit names.
Conclusion
Depending on your hardware and pool you might have to wait a day or so to see some rewards come your way. You can checkout this calculator to figure out what kind of return you can expect based on different variables.
Your best bet is to run this on a spare machine and leave it on for few days. You are probably not going to become the next crypto millionaire but it’s an excellent opportunity to learn more about the crypto space and Docker containers.
 The modern day crypto gold rush reminds me a little of Charles Nahl’s “Miners in the Sierras”
The modern day crypto gold rush reminds me a little of Charles Nahl’s “Miners in the Sierras”
May the odds be with you!
28 Aug 2017
Why?

As one of the Rails projects I’ve been working grew in size in terms of the number of lines of code as well as the number of people contributing code, it became challenging to maintain consistency in code quality and style.
Many times these issues were brought up in code reviews where they should be addressed well before that so the discussion in code reviews can focus on substance and not the style.
So having said that, I wanted to setup an automated way of fixing stylistic issues when the code is checked in. Here’s how I went about setting that up.
In my previous blog post, I talked about Incorporating Modern Javascript Build Tools With Rails, if you have something similar setup already, you can skip the next two sections about setting up a NodeJS environment. If not, read on.
NodeJS
Before we can get started, let’s make sure we have NodeJS installed. I’ve found the easiest way to do so is via nvm. Rails developers will find this very similar to rvm. To install, run the following commands which will install nvm and the latest version of NodeJS:
$ curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.32.1/install.sh | bash
$ source ~/.bash_profile
$ nvm install node
$ nvm use node
Yarn
Next we’ll need a package manager. Traditionally we’d use npm but I’ve found Facebook’s yarn to be a lot more stable and reliable to work with. This is very similar to bundler. To install on Debian Linux, run the following commands or follow their installation guide for your OS:
$ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
$ echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list
$ sudo apt-get update && sudo apt-get install yarn
Git Hook Management

Now in order to format the code automatically upon check-in, we will have to first figure out how to run those linting scripts. There are a couple of options:
1) Bash Script - You can manually save a bash script as .git/hooks/pre-commit and give it execute permission. Downside of this approach is that you’d have to have every member of your team do this manually. Also if something changes in the script, everyone would have to repeat the process all over again. It would quickly become unmanageable.
2) pre-commit - This is a very robust framework built in Python to manage git hooks. I really like everything about it except the fact that for RoR projects, it adds another language dependency on the local environment in addition to Ruby and NodeJS. Also again this is something the entire team would have to install manually (albeit only once per environment) to get it up and running. I would definitely recommend it for a Python project.
3) overcommit (Recommended) - This is another excellent git hook manager very similar to pre-commit but written in Ruby. It has a ton of built-in hooks for formatting Ruby, JS, CSS and more. It’s virtually plugin and play and perfect for a project if it doesn’t have a NodeJS build pipeline setup. It will help you avoid introducing another language dependency. Although for the purpose of this blog post, we’ll use the next option. I’ll recommend checking out this blog post if you want to use this option.
4) husky & lint-staged (Recommended) - These two NodeJS packages act as a one-two punch. Husky lets you specify any script that you want to run against git hooks right in the package.json while lint-staged makes it possible to run arbitrary npm and shell tasks with a list of staged files as an argument, filtered by a specified glob pattern on pre-commit. The best part, once this is setup, your team doesn’t have to do a thing other than run yarn install.
To get started install both the packages:
yarn add lint-staged husky --dev
Next add a hook for precommit in your package.json:
{
"scripts": {
"precommit": "lint-staged"
},
}
Lastly create an empty .lintstagedrc file at the root, this is where we’ll integrate with the various linters we’ll talk about next.
JavaScript

So now we are ready to actually hookup some linters. For JavaScript, there are several good linting frameworks out there ranging from very opinionated to very flexible:
1) StandardJS - This is the most opinionated framework out there and also very popular. It has excellent IDE integration and used by a lot of big names. Although having said that, we didn’t agree with some of it’s rules and there was no way of changing them. It is really designed to be a an install-it-and-forget-it kind of a linter which wasn’t quite what I was looking for.
2) Prettier - So that lead me to investigate another very popular framework. Prettier is a lot like StandardJS, good IDE support, well adopted. It tries to provide little more flexibility over a few basic rules compared to StandardJS. Although it’s main advantage over StandardJS is the fact that it is also able to lint CSS and GraphQL in additional to JavaScript and it’s preprocessors.
3) ESLint (Recommended) - After trying both of the above mentioned linters, I ended up settling with ESLint primarily for the fact that it let us tweak all the options exactly per our needs. The flexibility and extensibility of this framework is impressive.
So let’s go ahead and install it:
yarn install eslint --dev
Next you’ll want to run through setup and answer some questions about your preferences
./node_modules/.bin/eslint --init
Based on your responses, it will create an .eslintrc file in your project which you can always manually edit later. Here’s one that I’m using:
env:
browser: true
commonjs: true
es6: true
extends: 'eslint:recommended'
parserOptions:
sourceType: module
rules:
indent:
- warn
- 2
linebreak-style:
- warn
- unix
quotes:
- warn
- single
semi:
- warn
- always
no-undef:
- off
no-unused-vars:
- warn
no-console:
- off
no-empty:
- warn
no-cond-assign:
- warn
no-redeclare:
- warn
no-useless-escape:
- warn
no-irregular-whitespace:
- warn
I went with setting most of the rules as non-blocking warnings since we were dealing with some legacy code and wanted to reduce developer friction as much as possible.
Finally add this line to your .lintstagedrc
{
"*.js": ["eslint --fix", "git add"]
}
Ruby

When it came to Ruby linting, there is really just one game in town i.e RuboCop. All you need to do is add it to the Gemfile and run bundle install:
gem 'rubocop', require: false
Next add a hook for it in your .lintstagedrc:
{
"*.js": ["eslint --fix", "git add"],
"*.rb": ["rubocop -a -c .rubocop-linter.yml --fail-level E", "git add"],
}
Next you will need to create .rubocop-linter.yml with your coniguration. Here’s one that we used:
AllCops:
Exclude:
- 'vendor/**/*'
- 'spec/factories/**/*'
- 'tmp/**/*'
TargetRubyVersion: 2.2
Style/Encoding:
EnforcedStyle: when_needed
Enabled: true
Style/FrozenStringLiteralComment:
EnforcedStyle: always
Metrics/LineLength:
Max: 200
Metrics/ClassLength:
Enabled: false
IndentationConsistency:
EnforcedStyle: rails
Documentation:
Enabled: false
Style/ConditionalAssignment:
Enabled: false
Style/LambdaCall:
Enabled: false
Metrics:
Enabled: false
Also here’s a list of all the auto corrections RuboCop is able to do when the -a / --auto-correct flag is turned on if you need to add/change any more rules in that file.
CSS/SCSS

So now that we have Ruby and JS linting squared away. Let’s look into how to do the same with CSS.
1) sass-lint - Since we were using SASS in the project, I first looked at this package. Although quickly realized there was no option for auto fixing available at the moment. There is a PR which is currently in the works that is supposed to add this feature at some point. But for now we’ll have to look somewhere else.
2) stylelint (Recommended) - Ended up going with this option because of its large ruleset (150 at the time of writing) and the fact that it is powered by PostCSS which understands any syntax that PostCSS can parse, including SCSS, SugarSS, and Less. Only downside being the fact that auto fixing feature is experimental but it’s worth a shot anyway.
So let’s go ahead and install it:
Next add a hook for it in your .lintstagedrc:
{
"*.js": ["eslint --fix", "git add"],
"*.rb": ["rubocop -a -c .rubocop-linter.yml --fail-level E", "git add"],
"*.scss": ["stylelint --fix", "git add"]
}
Again this is a very configurable package with a lot of options which you can manage in a .stylelintrc file.
To being with, I’d probably just recommend extending either stylelint-config-standard or stylelint-config-recommended presets.
Here’s an example of a .stylelintrc:
{
"extends": "stylelint-config-standard",
"rules": {
/* exceptions to the rule go here */
}
}
HAML

As far as templating engine goes, our project uses HAML but unfortunately I couldn’t find any auto formatting solution for it. haml-lint has an open ticket for adding this feature but it seems like it’s not very easy to implement.
So until then you have the option to just hook up the linter so it can provide feedback about your markup which you would have to manually correct.
To get started, add the gem to your Gemfile:
gem 'haml_lint', require: false
Next add a hook for it in your .lintstagedrc:
{
"*.js": ["eslint --fix", "git add"],
"*.rb": ["rubocop -a -c .rubocop-linter.yml --fail-level E", "git add"],
"*.scss": ["stylelint --fix", "git add"]
"*.haml": ["haml-lint -c .haml-lint.yml", "git add"],
}
Next you will need to create .haml-lint.yml with your configuration. Here’s one that you can use:
# Whether to ignore frontmatter at the beginning of HAML documents for
# frameworks such as Jekyll/Middleman
skip_frontmatter: false
linters:
AltText:
enabled: false
ClassAttributeWithStaticValue:
enabled: true
ClassesBeforeIds:
enabled: true
ConsecutiveComments:
enabled: true
ConsecutiveSilentScripts:
enabled: true
max_consecutive: 2
EmptyScript:
enabled: true
HtmlAttributes:
enabled: true
ImplicitDiv:
enabled: true
LeadingCommentSpace:
enabled: true
LineLength:
enabled: false
MultilinePipe:
enabled: true
MultilineScript:
enabled: true
ObjectReferenceAttributes:
enabled: true
RuboCop:
enabled: false
RubyComments:
enabled: true
SpaceBeforeScript:
enabled: true
SpaceInsideHashAttributes:
enabled: true
style: space
TagName:
enabled: true
TrailingWhitespace:
enabled: true
UnnecessaryInterpolation:
enabled: true
UnnecessaryStringOutput:
enabled: true
Optionally, you can also exclude all the existing HAML files with linting issues by running the following command and including the exclusions file (inherits_from: .haml-lint_todo.yml) in the configuration file above to ease the on-boarding process:
haml-lint --auto-gen-config
Conclusion
That’s all folks! In a few weeks since hooking up the auto formatters our codebase has started to look much more uniform upon every commit. Code reviews can now focus on more important feedback.

{kind=link}